
- Що таке пошуковий робот та як він працює
- Які бувають пошукові роботи
- Навіщо власнику сайту знати про пошукових роботів
- Як керувати пошуковими роботами: файл robots.txt та інші інструменти
Велике навантаження на сервер, відсутність у видачі цільових сторінок та наявність непотрібних — це лише частина труднощів, які виникають через нерозуміння принципу функціонування пошуковиків. Вони використовують спеціальні програми для сканування сайтів, щоб потім надавати релевантні посилання на запити користувача. Якщо знати, що таке пошуковий робот та вміти спрямовувати його в потрібному напрямку, вдасться не лише уникнути розповсюджених проблем. Ви зможете поліпшити швидкість індексації, оптимізувати веб-ресурс для мобільних пристроїв, швидше виявляти та усувати технічні помилки, тобто покращити SEO та збільшити відвідуваність!
Читайте також: Погані боти: чим вони шкодять сайту і як їх заблокувати
Що таке пошуковий робот та як він працює
Пошуковий робот (веб-паук, веб-сканер, краулер) — це програмне забезпечення, яке пошуковики використовують для збору інформації про сайт. Спочатку веб-павук переходить на сторінку та сканує її вміст, а потім передає інформацію до бази даних Google (Bing, Yahoo!). А вже на основі отриманих відомостей пошуковик відповідає на запит користувача: надає найбільш релевантні відповіді та ранжує їх за певними критеріями.
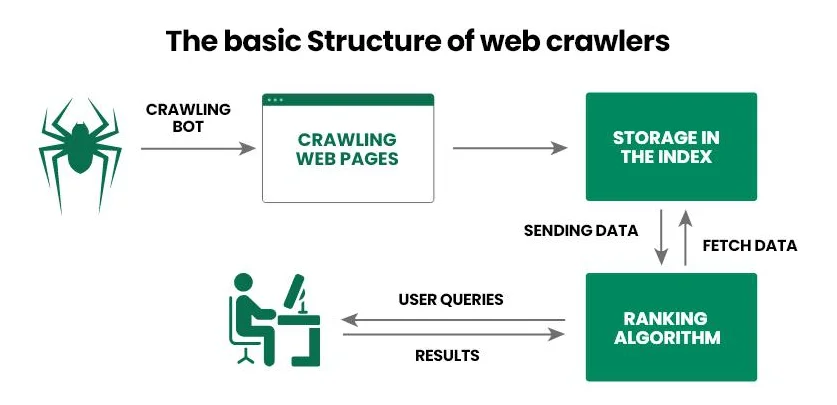
Розглянемо принцип функціонування пошукового робота крок за кроком:
- Оператор надає краулеру стартовий набір URL, наприклад, список посилань на популярні інтернет-проєкти.
- Веб-павук переходить за посиланнями, аналізує HTML-код документа (метадані, текст, зображення тощо) та інші лінки (внутрішні і зовнішні). Крім того, сучасні веб-павуки можуть також обробляти JavaScript, що робить їх здатними сканувати динамічний контент.
- Отримані відомості пошуковий робот передає в базу даних (індекс) для подальшого детального вивчення та зберігання.
- Пошуковик визначає релевантність сторінки для конкретних запитів та присвоює їй рейтинг, від якого потім залежить позиція в видачі.
- Після оновлення інформації на вже проіндексованій сторінці, веб-павук на неї повертається, фіксує зміни та знову передає відомості в базу даних.
Читайте також: Що таке robots.txt і як налаштувати robots.txt для WordPress
Головна задача пошукового робота — просканувати веб-сторінку для подальшого індексування пошуковиком. Так пошукові системи завжди мають актуальну інформацію про вміст інтернет-проекту, користувачі — швидко отримують відповідь на свій запит, а власники сайтів — розуміють, що потрібно покращити, щоб вивести веб-сторінку на перші позиції у видачі.

Які бувають пошукові роботи
Великі пошуковики мають власних веб-павуків, яких використовують для сканування веб-сторінок та індексації контенту. Знаючи цих роботів, ви можете заблокувати їм доступ до свого веб-ресурсу або, навпаки, отримати доступ до інструментів для прискорення індексації.
Найбільш відомими є наступні пошукові роботи:
- Googlebot. Використовується пошуковиком Google. Є два окремі краулери: Desktop сканує комп'ютерну версію сайту, а Mobile — мобільну.
- Bingbot. Допомагає пошуковику Bing отримувати актуальну інформацію про веб-ресурси та проводити ранжування за власними алгоритмами.
- Slurp Bot. Використовується для спрощеного формування результатів видачі в пошуковій системі Yahoo!.
- DuckDuckBot. Веб-павук пошуковика DuckDuckGo, який при скануванні веб-ресурсу приділяє особливу увагу захисту користувачів.
- Exabot. Краулер маловідомої французької пошукової системи Exalead, створений для сканування та індексації сайтів за власними правилами.
Серед українських веб-майстрів найбільш відомим є Googlebot, яким можна керувати за допомогою Google Search Console (далі ми детальніше розглянемо цей процес). Власники англомовних інтернет-проектів роблять ставку не лише на Googlebot, а й на Bingbot та Slurp Bot, що пояснюється великим попитом на пошукові системи Bing та Yahoo!.
Читайте також: SEO на мінімалках — що власник сайту може зробити самостійно для просування сайту без залучення спеціалістів
Навіщо власнику сайту знати про пошукових роботів
Читаючи матеріал, ви могли подумати: «Є різні пошукові роботи, вони добре виконують свої задачі, але навіщо мені взагалі про них знати». Розуміння принципу функціонування веб-павуків та знання найвідоміших з них дає змогу безпосередньо впливати на ефективність просування сайту в видачі. Ви можете заборонити певним краулерам доступ до ресурсу, оптимізувати документ, покращити структуру інтернет-проєкту, повідомити веб-сканеру про оновлення інформації або додавання нової сторінки. Так ви зможете прискорити індексацію та підвищити шанси на отримання кращої позиції у видачі, відповідно, збільшити кількість цільових відвідувачів.
Розберемо, як використовувати знання про пошукових роботів в SEO:
- Оптимізувати файл robots.txt. Програмне забезпечення слідує інструкціям не лише пошукової системи, а й власника веб-ресурсу. Для цього воно використовує robots.txt — файл, де вказано, які сторінки можна сканувати, а які треба ігнорувати.
- Уникати дублікатів. Інколи на сайті можуть виникати дублікати контенту, що заплутує пошукових роботів, відповідно, знижує позиції у видачі. Для вирішення проблеми ви можете використовувати канонічні теги та редиректи (перенаправлення).
- Робити перелінковку. Пошукові роботи приділяють велику увагу внутрішнім та зовнішнім посиланням. Ви можете використати цю інформацію, наприклад, зв'язати лінками старі та нові статті. Коли нові сторінки мають внутрішні посилання з уже проіндексованих, це допомагає прискорити їх перевірку.
- Налаштувати мапу сайту. Ми рекомендуємо використовувати дві мапи сайту — для пошукових роботів (sitemap.xml, подається через інструменти для вебмайстрів) та для користувачів (sitemap.html). Хоча друга призначена для відвідувачів веб-ресурсу, вона може допомогти і краулерам, адже, як ви пам'ятаєте, аналізуючи сторінку вони переходять по всім відкритим присутнім лінкам.
- Підвищувати авторитетність. Веб-павуки надають перевагу доменним іменам з хорошою історією. Ви можете використати цей момент: побудуйте стратегію лінкбілдингу, щоб отримати посилання з авторитетних інтернет-проектів, відповідно, підвищити авторитетність свого сайту.
- Усувати технічні помилки. Одна з задач власника веб-ресурсу — забезпечити пошуковим роботам вільний доступ до сторінок. Для цього слід відстежувати помилки 404 та 500, проблеми з редиректами, пошкоджені посилання, неоптимізовані скрипти та стилі тощо.
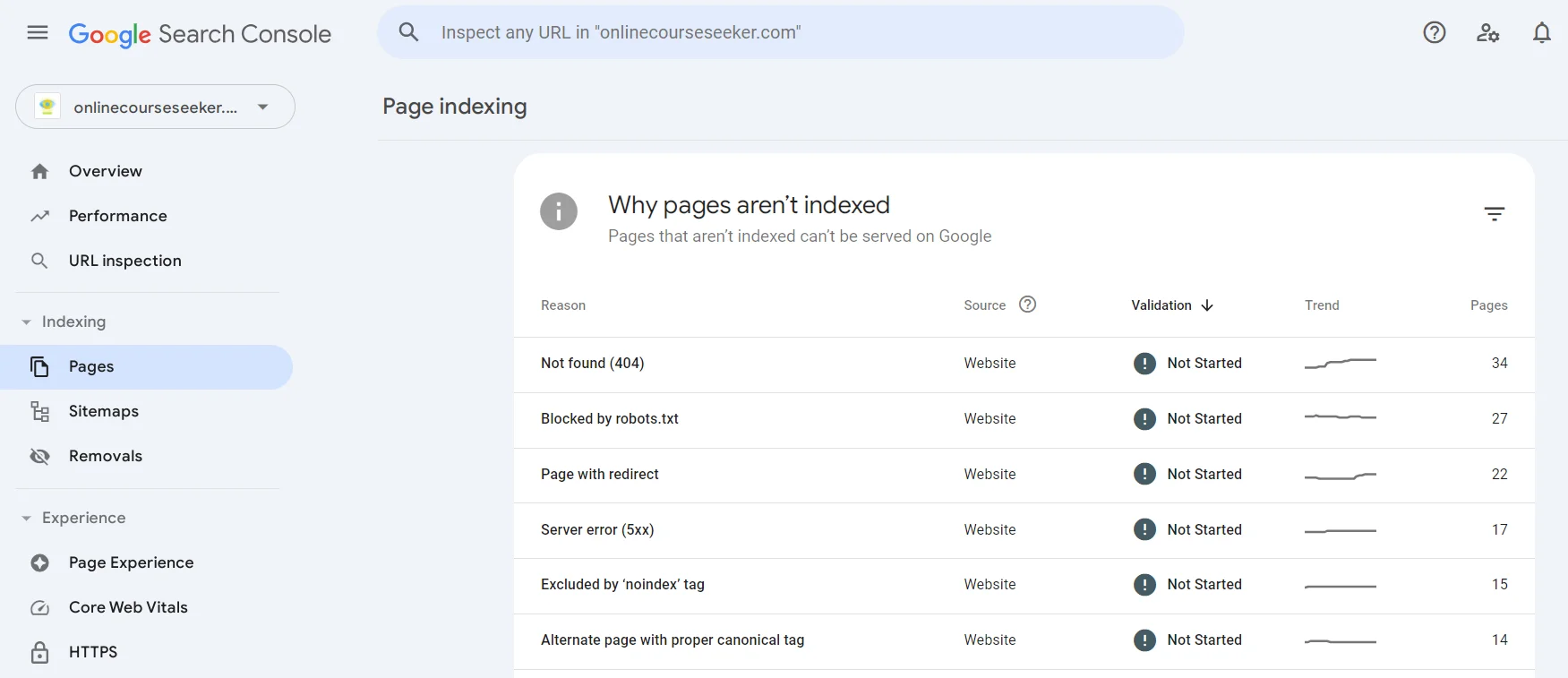
А знайти сторінки, які не вдалося проіндексувати, можна в Google Search Console в розділі Pages. Ви можете перейти до будь-якої наявної проблеми (Not found, Page with redirect, Excluded by «noindex» tag тощо), дізнатися про неї більше та знайти список сторінок, які не були через неї проіндексовані.
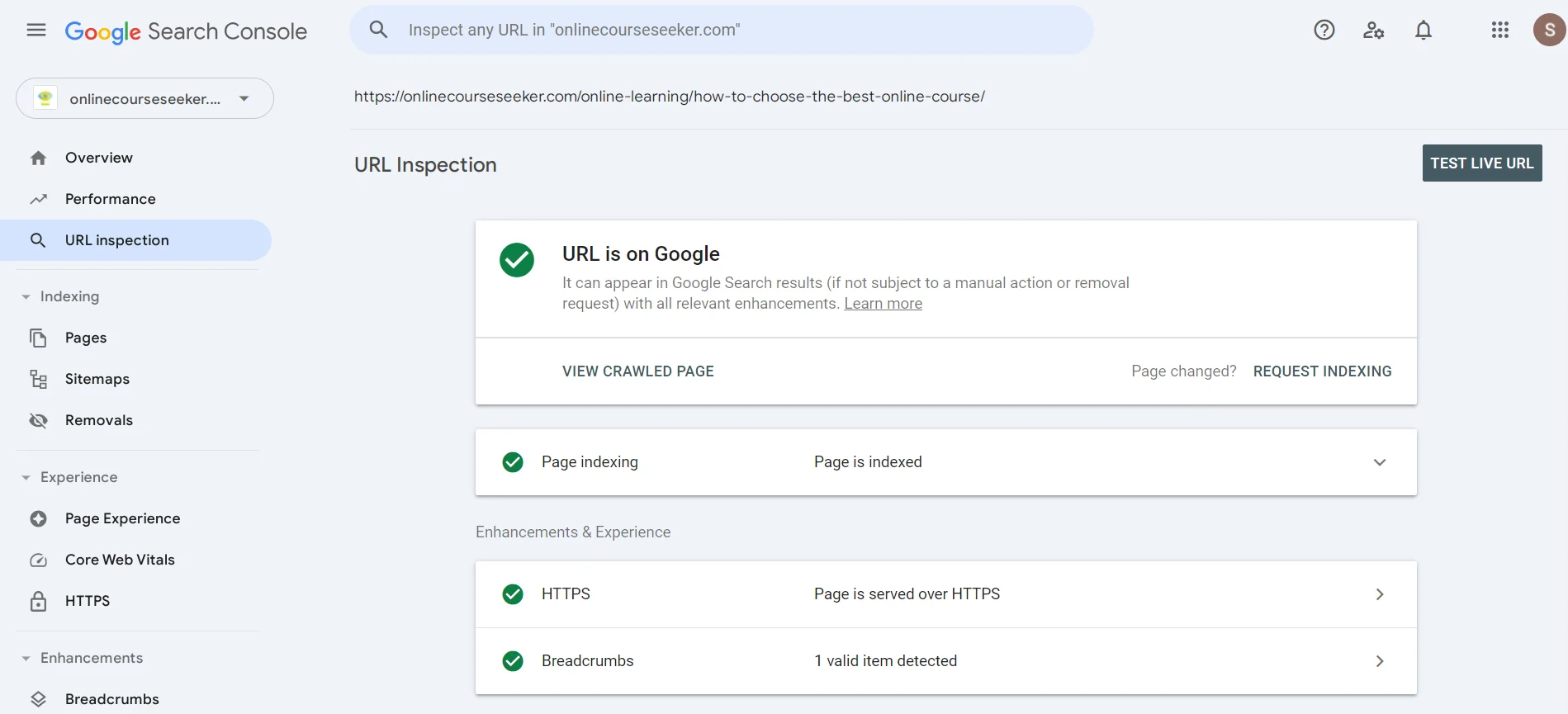
В пошуку можна вказати URL з метою дізнатися, чи проаналізував вже пошуковий робот сторінку. Якщо побачите повідомлення про відсутність індексації, можете натиснути Request Indexing, тобто відправити краулеру повідомлення, щоб він незабаром звернув увагу на вашу сторінку.
Читайте також: Як побудувати сильний посилальний профіль сайту у 2024 році
Як керувати пошуковими роботами: файл robots.txt та інші інструменти
Файл robots.txt — це текстовий файл для керування доступом пошукових роботів до різних частин сайту. Його можна створити за допомогою звичайного текстового редактора, наприклад, Notepad, та додати в кореневу директорію веб-ресурсу через панель керування хостингу або FTP-клієнт.
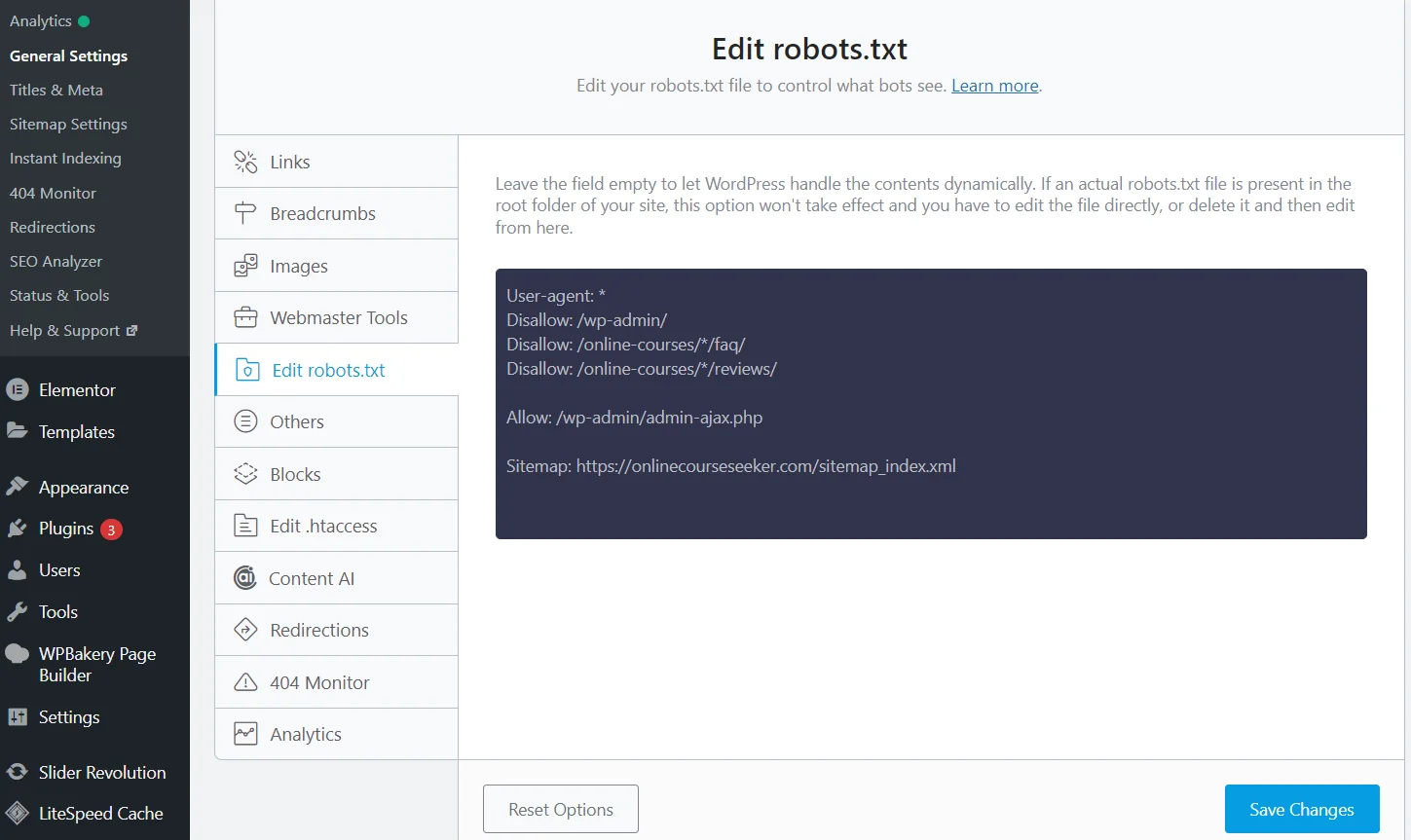
Редагування robots.txt з плагіном Rank Math SEO
Але є набагато простіший спосіб — SEO плагіни. Достатньо встановити та активувати плагін Rank Math (Yoast, All in One або інший), після чого система створить файл robots.txt. До того ж вона буде автоматично його оновлювати, а відредагувати дані можна прямо на сайті, завдяки чому не потрібно переходити в панель керування хостингу.
Ви можете використовувати спеціальні правила, щоб заборонити сканування певних сторінок/директорій:
- Конкретна сторінка. Наприклад, потрібно закрити сторінку для клієнтів `https://example.com/private-page`. Додайте в robots.txt правило
User-agent: *
Disallow: /private-page
- Вся директорія. Заборонити сканування всієї директорії, наприклад, `https://example.com/private/` допоможе код
User-agent: *
Disallow: /private/
- Тип файлів. Закрити від пошукових роботів певні типи файлу, наприклад, .pdf допомагає правило
User-agent: *
Disallow: /*.pdf$
Важливо: robots.txt містить набір правил, але пошукові роботи можуть їм не слідувати. Щоб точно закрити сторінку від індексації, рекомендуємо додатково додати метатег `noindex` в HTML-код сторінки:
meta name="robots" content="noindex"
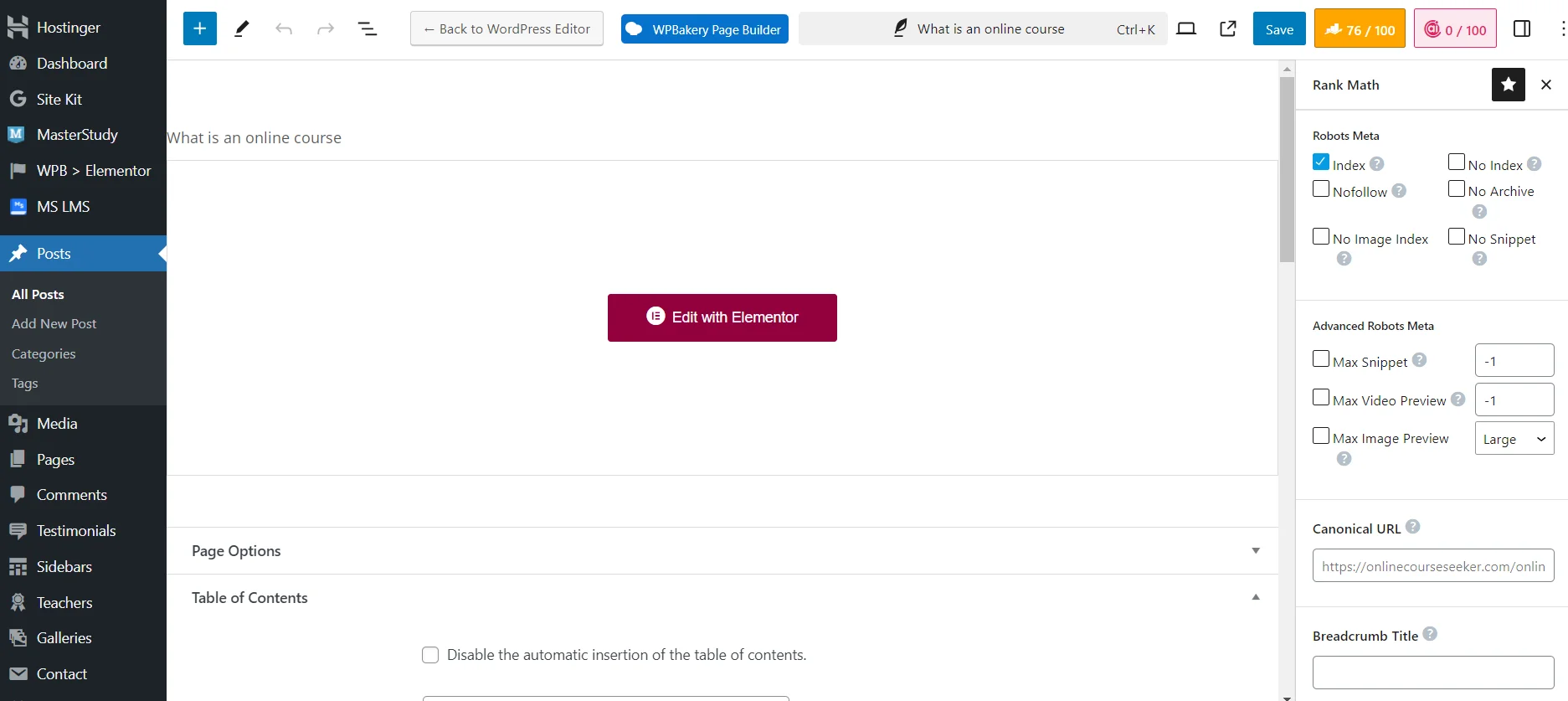
Налаштування видимості сторінки сайту для пошукових роботів з плагіном Rank Math SEO
Хоча набагато простіше закривати сторінки від індексації через SEO плагін. Вам достатньо використати потрібні технічні налаштування під час додавання або редагування сторінки. Наприклад, можете поставити `No Index`, щоб повністю закрити матеріал від пошукових роботів. Або `No Image Index`, щоб закрити від індексації лише зображення.
Пошукові роботи — важливі програми, які суттєво спрощують функціонування пошуковиків, дозволяючи їм швидко знаходити та ранжувати сайти. Якщо оптимізуєте файл robots.txt, вирішите технічні проблеми, налаштуєте мапи, зробите перелінковку, то вам вдасться спростити краулерам доступ до потрібних частин веб-ресурсу. А це дозволить покращити позиції цих сторінок в пошуковій видачі, відповідно збільшити кількість цільових відвідувачів!








