Більше 20 років інформація з усіх сайтів, які існують в мережі, архівується та зберігається у відкритому доступі. Веб архів сайтів — це можливість мандрувати в часі та дізнаватися, який контент був розміщений на сайтах у різні періоди їхнього існування. Ця інформація не лише потрібна для роботи, а і просто цікава. Погодьтеся, ви б хотіли дізнатися, який вигляд мав Google або Facebook на початку свого шляху? Це може зробити будь-який користувач інтернету.
У цій статті ми розповімо, як дізнатися історію сайту з веб-архіву, що являє собою сам проект, звідки він узявся та хто його створив.
Історія створення Wayback Machine
У кінці 1990-х років двоє винахідників Брюстер Кале і Брюс Джилліат задумалися над проблемою збереження цифрового контенту, розміщеного на сайтах. Якщо власник веб-ресурсу не має грошей на те, щоб оплатити домен або просто не зацікавлений у подальшій підтримці сайту, всі розміщені на ньому матеріали просто зникають. В той час як газети, книги чи фільми архівуються та зберігаються, інтернет-простір став єдиним джерелом інформації, яка доступна тільки в режимі реального часу.
У 2001 році вони створили неприбуткову організацію Internet Archive з дуже серйозними намірами — заархівувати весь інтернет. Проект з пошуку та збереження веб-сторінок був запущений раніше, у 1996 році, та називався Wayback Machine — за аналогією з машиною часу.
За п’ять років роботи до моменту офіційного відкриття проект вже назбирав понад десять мільярдів сторінок. А у 2020 році веб-архів сайтів містив 70 петабайтів даних (в одному петабайті — 1024 терабайтів). Зараз на його виділених серверах зберігається 625 мільярдів веб-сторінок.

Для чого можна використовувати веб-архів
Цей цікавий інструмент у першу чергу потрібен для тих, хто працює із сайтами.
Пошуковий робот веб-архіву періодично заходить на сторінки веб-ресурсу та зберігає всі матеріали сайту.
Кількість сканувань краулера Wayback Machine не пов'язана напряму з оновленнями на сайті, а відбувається за власним графіком.
Такі архіви мають практичну користь в багатьох різних випадках.
При покупці домена
Реєструючи домен, ви не можете знати, чи він новий, чи вже був у когось у використанні. І тільки перевірка його історії у веб-архіві може показати, чи було щось розміщено на ньому раніше. Ця інформація важлива з кількох причин. Google «любить» старі домени — їх простіше просувати у видачі, ніж нові. Якщо вам дісталась така адреса, то цю ситуацію можна використати по максимуму для розкрутки сайту. Але може бути і «темний» бік у домена, який мав інших власників до того. Тому важливо не лише те, як давно створений домен, а і що саме було на ньому розміщене.
Часто веб-майстри цілеспрямовано шукають дроп-домени (з історією), щоб швидше просувати сайт. Перед реєстрацією такої адреси перевіряється багато різних нюансів, серед яких історія контенту сайту.
Для розміщення партнерських посилань
Розвиваючи посилальний профіль, лінкбілдери домовляються з різними майданчиками про розміщення посилань на свій сайт. Часто це працює як обмін посиланнями.
Репутація веб-ресурсу, з яким планується співпраця, має велике значення. Для цього перевіряється його посилальний профіль, органічний трафік, вік домену та історія сайту. Найвище цінується співпраця зі старими сайтами, які розвивалися багато років на одній адресі. Посилання від таких донорів Google сприймає як якісні. І навпаки — посилання з сайтів з сумнівною історією можуть тільки зашкодити посилальному профілю.
Щоб знайти видалений контент
Якщо контент видалений із сайту, є велика вірогідність відновити його з веб-архіву. Причини такої потреби можуть бути дуже різні — від пошуку випадково видаленого контенту власного сайту (хоча для цього краще створювати резервні копії) до статей на чужих сайтах, які можуть знадобитися для підтвердження оприлюднення інформації (наприклад, потрібно довести факт публікації новини).
Таким чином можна не лише знайти окрему сторінку, а і відновити цілком весь сайт.
Для дослідження історії розвитку IT-технологій
Розробники, веб-дизайнери, копірайтери, ілюстратори сайтів потребують розуміння, як змінювався та розвивався Інтернет та окремі веб-ресурси. Wayback Machine — це невичерпне джерело для вивчення сайтів у різні роки їхнього існування на живих прикладах. Це дійсно той випадок, коли можна сісти в машину часу і побачити все на власні очі.
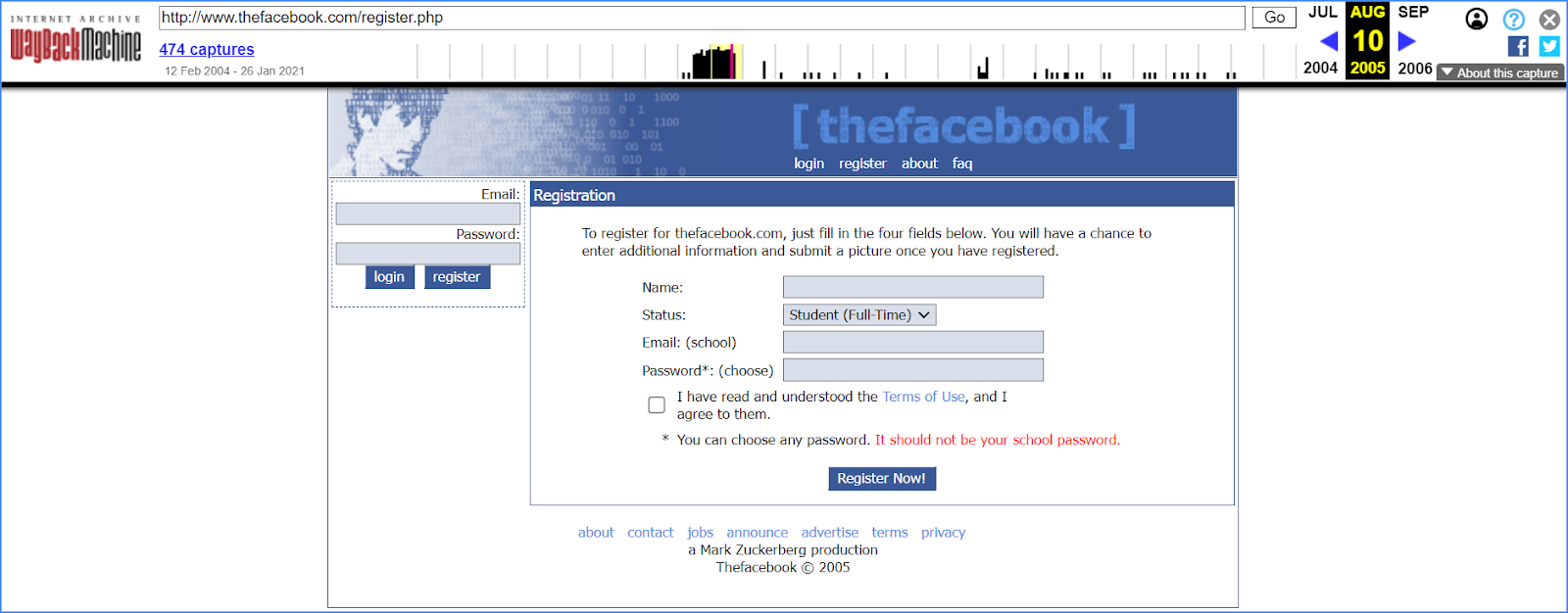 Наприклад, за допомогою веб-архіва ми можемо дізнатися, як виглядав Facebook тоді, коли був мережею для студентів у 2005 році, і ніхто навіть не здогадувався, що він перетвориться на бізнес із мільярдними прибутками.
Наприклад, за допомогою веб-архіва ми можемо дізнатися, як виглядав Facebook тоді, коли був мережею для студентів у 2005 році, і ніхто навіть не здогадувався, що він перетвориться на бізнес із мільярдними прибутками.
Архів сайтів може розповісти і ще дещо — до 2005 року сайт на домені facebook.com пропонував купити софт AboutFace, який мав на меті допомогти компаніям у створенні телефонних каталогів працівників. Головною фішкою таких електронних довідників була наявність не лише контактів, а і фото людини. Як бачите, у цьому проекті вже проглядають риси майбутньої соцмережі.
Але є невідповідність: в усіх джерелах вказана дата заснування соцмережі у 2004 році, але її інтерфейс з’являється на домені тільки у 2005-му. Відповідь проста — у свій перший рік стартап містився на домені thefacebook.com. Він і досі існує та здійснює редирект на основну адресу.
Як бачите, можна багато дізнатися про історію сайту, вивчивши його у веб-архіві.
Читайте також: «Як малювати в Midjourney: нейромережа генерує зображення за текстовими запитами».
Wayback Machine — як користуватися архівом сайтів
Перейдіть за посиланням на сайт веб-архіву. Далі потрібно ввести в пошуковий рядок адресу сайту, і сервіс видасть всю статистику.
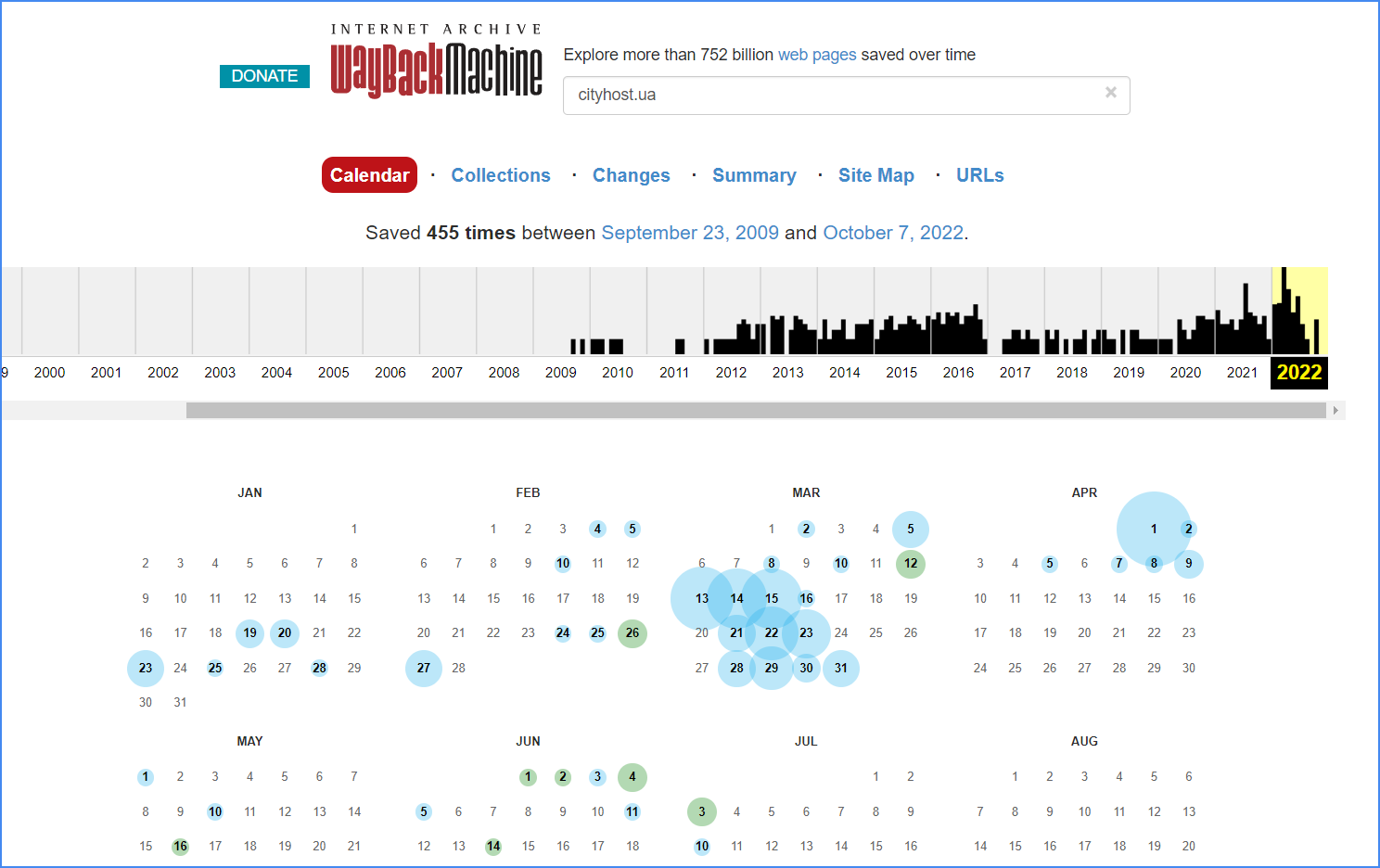
Вгорі ви побачите графік активності краулера, побудований на основі кількості снапшотів. Нижче буде календар, у якому ці снапшоти зафіксовані. Подивитися стан сайту можна тільки за ті дати, які відмічені синіми та зеленими колами — саме за ці дні є збережені знімки сайту. Далі вибираєте один зі снапшотів, клікаєте по ньому, і перед вами відкривається відповідна версія сайту.
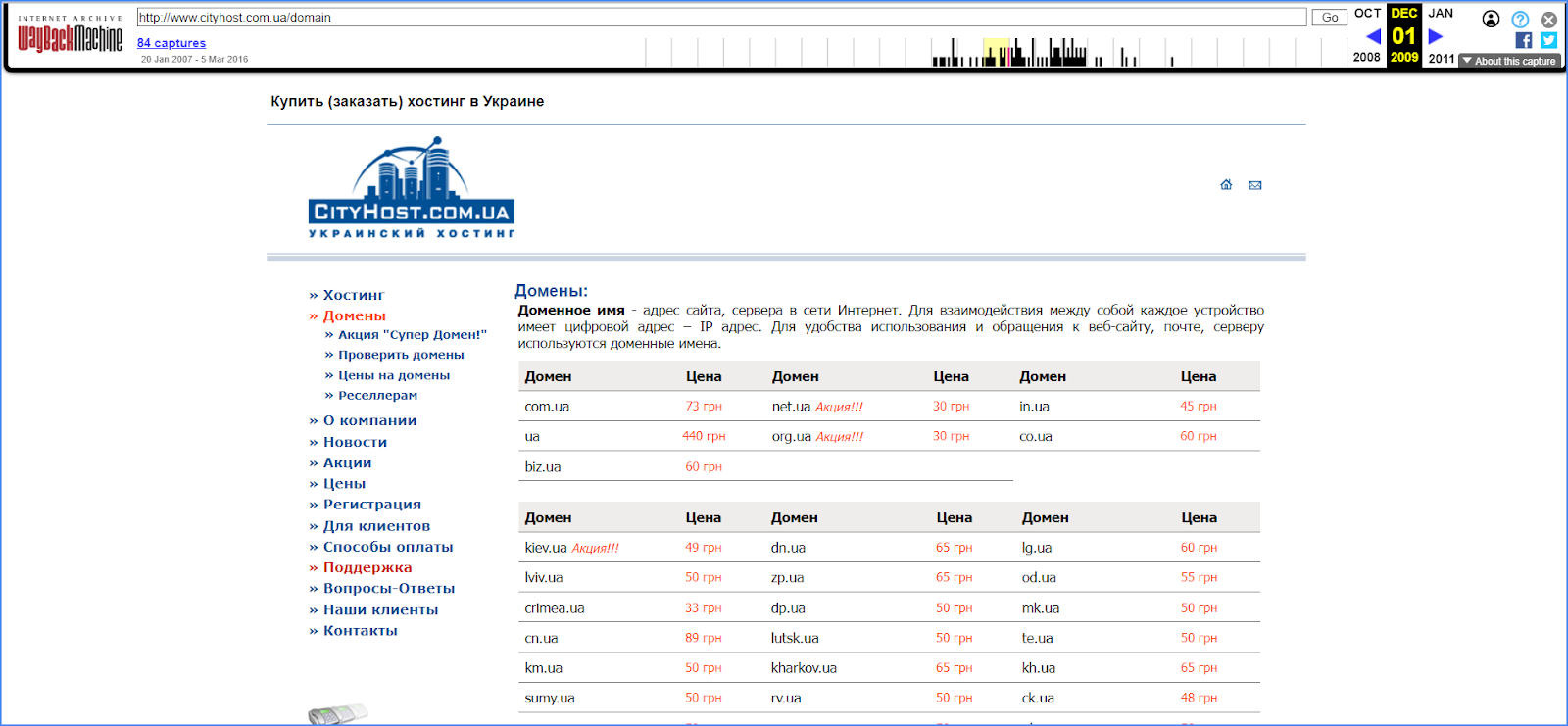
Всі посилання з меню у веб-архіві працюють, тож ви можете погуляти по всьому сайту і побачити всі розділи. Ось такий вигляд, наприклад, мав сайт Cityhost.ua у далекому 2009 році.
Читайте також: «Розміщуємо сайт в Інтернеті — які послуги купувати і скільки вони коштують»
Крім домена, у пошуковий рядок можна вводити і ключове слово — тоді ви отримаєте список сайтів, які просуваються по цьому ключу.
Інші розділи Internet Archive
Команда інтернет-архіву вирішила зберігати не лише сайти, а і «культурні артефакти у цифровій формі», я вони це самі називають. Це окремі файли, у яких міститься цінний контент — відео, фото, тексти, аудіо.
Web archive — це лише частина проекту. Крім нього на сайті Internet archive є ще 5 розділів:
-
Тексти
-
Відео
-
Аудіо
-
Софт
-
Зображення
В інтернет-архіві можна знайти багато аудіокниг (здебільшого англійською мовою), записи з радіостанцій, документальні відео, архіви газет, випуски новин, художні фільми, музику, старі програми та ігри.
Наприклад, ось такі цікаві раритети вдалося знайти у нетрях архіву:
-
Звіт NASA за 1977 рік (запуск шаттла та Вояджерів)
-
Аудіозапис джазового концерту для радіо
-
Super Mario 1994 (можна пограти прямо на сайті)
Ми спеціально підібрали радикально різні зразки, щоб показати все різноманіття матеріалу, який зберігається в інтернет-архіві.
Але не обов’язково всі розміщені в ньому файли старі — є багато і нового контенту, який архівується просто зараз. Колись і він стане історичним надбанням.
Нині в інтернет-архіві нараховується:
-
38 мільйонів книг і текстів
-
4 мільйони зображень
-
790 000 програм
-
14 мільйонів аудіозаписів (включаючи 240 000 живих концертів)
-
7 мільйонів відео (включаючи 2 мільйони програм телевізійних новин)
Все це багатство може допомогти не лише спеціалістам з IT-сфери, а і з будь-якої іншої галузі знайти необхідну інформацію. Багато цих файлів відкрито доступні тільки в інтернет-архіві, що перетворює його на унікальну колекцію цифрових даних.