Более 20 лет информация со всех сайтов, существующих в сети, архивируется и хранится в открытом доступе. Веб архив сайтов — это возможность путешествовать по времени и узнавать, какой контент был размещен на сайтах в разные периоды их существования. Эта информация не только необходима для работы, но и просто интересна. Согласитесь, вы бы хотели узнать, как выглядел Google или Facebook в начале своего пути? Это может сделать любой пользователь Интернета.
В этой статье мы расскажем, как узнать историю сайта из веб-архива, что представляет собой сам проект, откуда он взялся и кто его создал.
История создания Wayback Machine
В конце 1990-х годов два изобретателя Брюстер Кале и Брюс Джиллиат задумались над проблемой сохранения цифрового контента, размещенного на сайтах. Если владелец веб-ресурса не имеет денег на то, чтобы оплатить домен или просто не заинтересован в дальнейшей поддержке сайта, все размещенные на нем материалы просто исчезают. В то время как газеты, книги или фильмы архивируются и хранятся, интернет-пространство стало единственным источником информации, доступной только в режиме реального времени.
В 2001 году они создали некоммерческую организацию Internet Archive с очень серьезными намерениями — заархивировать весь интернет. Проект по поиску и сохранению веб-страниц был запущен раньше, в 1996 году, и назывался Wayback Machine — по аналогии с машиной времени.
За пять лет работы к моменту официального открытия проект уже насобирал более десяти миллиардов страниц. А в 2020 году веб-архив сайтов содержал 70 петабайтов данных (в одном петабайте – 1024 терабайтов). Сейчас на его выделенных серверах хранится 625 миллиардов веб-страниц.

Для чего можно использовать веб-архив
Этот интересный инструмент в первую очередь нужен для тех, кто работает с сайтами.
Поисковый робот веб-архива периодически заходит на страницы веб-ресурса и сохраняет все материалы сайта.
Количество сканирований краулера Wayback Machine не связано напрямую с обновлениями на сайте, а происходит по собственному графику.
Такие архивы имеют практическую пользу во многих разных случаях.
При покупке домена
Регистрируя домен, вы не можете знать, новый он или уже был у кого-то в использовании. И только проверка его истории в веб-архиве может показать, было ли что-то размещено на нем раньше. Эта информация важна по нескольким причинам. Google «любит» старые домены — их проще продвигать в выдаче, чем новые. Если вам достался такой адрес, то эту ситуацию можно использовать по максимуму для раскрутки сайта. Но может быть и «темная» сторона у домена, у которого раньше были другие владельцы. Поэтому важно не только то, как давно создан домен, но и что именно было на нем размещено.
Часто веб-мастера целенаправленно ищут дроп-домены (с историей), чтобы быстрее продвигать сайт. Перед регистрацией такого адреса проверяется много разных нюансов, среди которых история контента сайта.
Для размещения партнерских ссылок
Развивая ссылочный профиль, линкбилдеры договариваются с разными площадками о размещении ссылок на свой сайт. Часто это работает как обмен ссылками.
Репутация веб-ресурса, с которым планируется сотрудничество, имеет большое значение. Для этого проверяется его ссылочный профиль, органический трафик, возраст домена и история сайта. Выше всего ценится сотрудничество со старыми сайтами, которые развивались много лет на одном адресе. Ссылки от таких доноров Google воспринимает как качественные. И наоборот — ссылки с сайтов с сомнительной историей могут только повредить ссылочному профилю.
Чтобы найти удаленный контент
Если контент удален с сайта, существует большая вероятность восстановить его из веб-архива. Причины такой потребности могут быть очень разные — от поиска случайно удаленного контента собственного сайта (хотя для этого лучше создавать резервные копии) до статей на чужих сайтах, которые могут понадобиться для подтверждения обнародования информации (например, нужно доказать факт публикации новости).
Таким образом, можно не только найти отдельную страницу, но и восстановить полностью весь сайт.
Для исследования истории развития IT-технологий
Разработчики, веб-дизайнеры, копирайтеры, иллюстраторы сайтов нуждаются в понимании, как изменялся и развивался Интернет и отдельные веб-ресурсы. Wayback Machine — это неисчерпаемый источник для изучения сайтов в разные годы их существования на живых примерах. Это действительно тот случай, когда можно сесть в машину времени и увидеть все своими глазами.
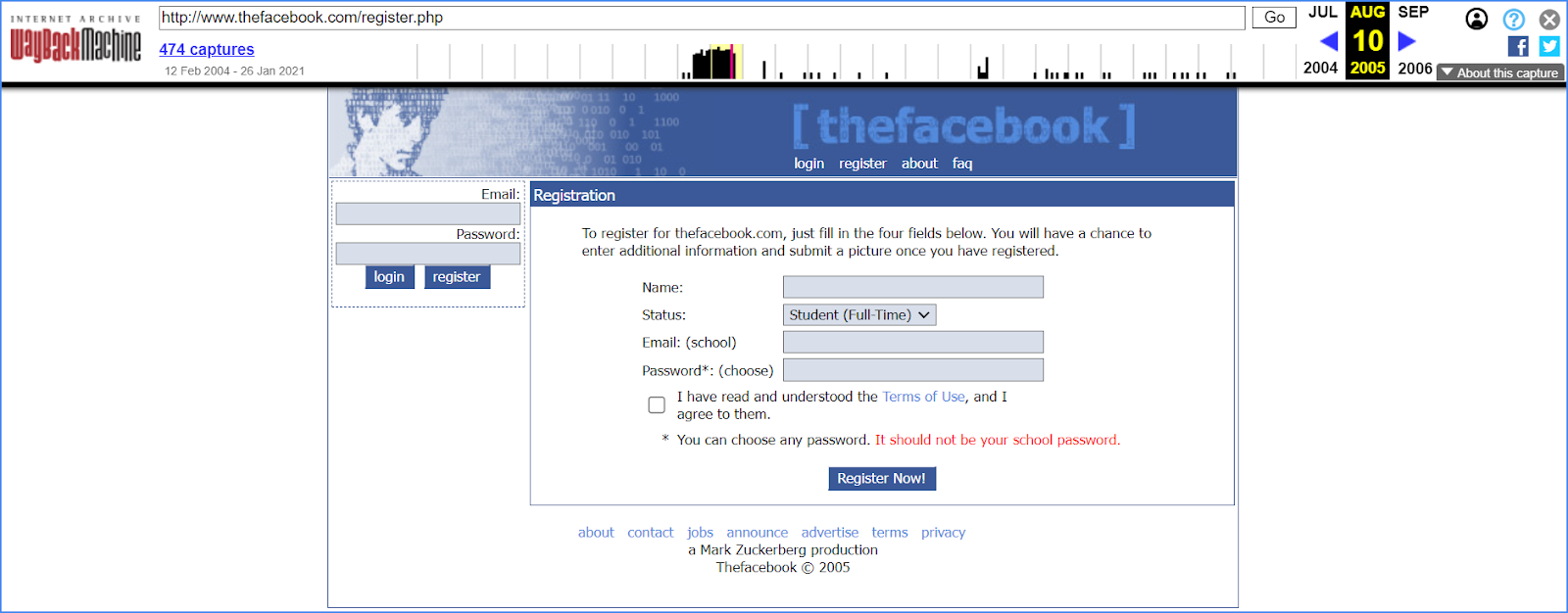
К примеру, с помощью веб-архива мы можем узнать, как выглядел Facebook тогда, когда был сетью для студентов в 2005 году, и никто даже не догадывался, что он превратится в бизнес с миллиардными доходами.
Архив сайтов может рассказать и еще кое-что — до 2005 года сайт на домене facebook.com предлагал купить софт AboutFace, который имел цель помочь компаниям в создании телефонных каталогов работников. Главной фишкой таких электронных справочников было наличие не только контактов, но и фото человека. Как видите, в этом проекте уже просматриваются черты будущей соцсети.
Но есть несоответствие: во всех источниках указана дата основания соцсети в 2004 году, но ее интерфейс появляется на домене только в 2005-м. Ответ прост – в свой первый год стартап размещался на домене thefacebook.com. Он до сих пор существует и осуществляет редирект на основной адрес.
Как видите, можно многое узнать об истории сайта, изучив его в веб-архиве.
Читайте также: «Как рисовать в Midjourney: нейросеть генерирует изображение по текстовым запросам».
Wayback Machine — как пользоваться архивом сайтов
Перейдите по ссылке на сайт веб-архива. Далее нужно ввести в поисковую строчку адрес сайта, и сервис выдаст всю статистику.
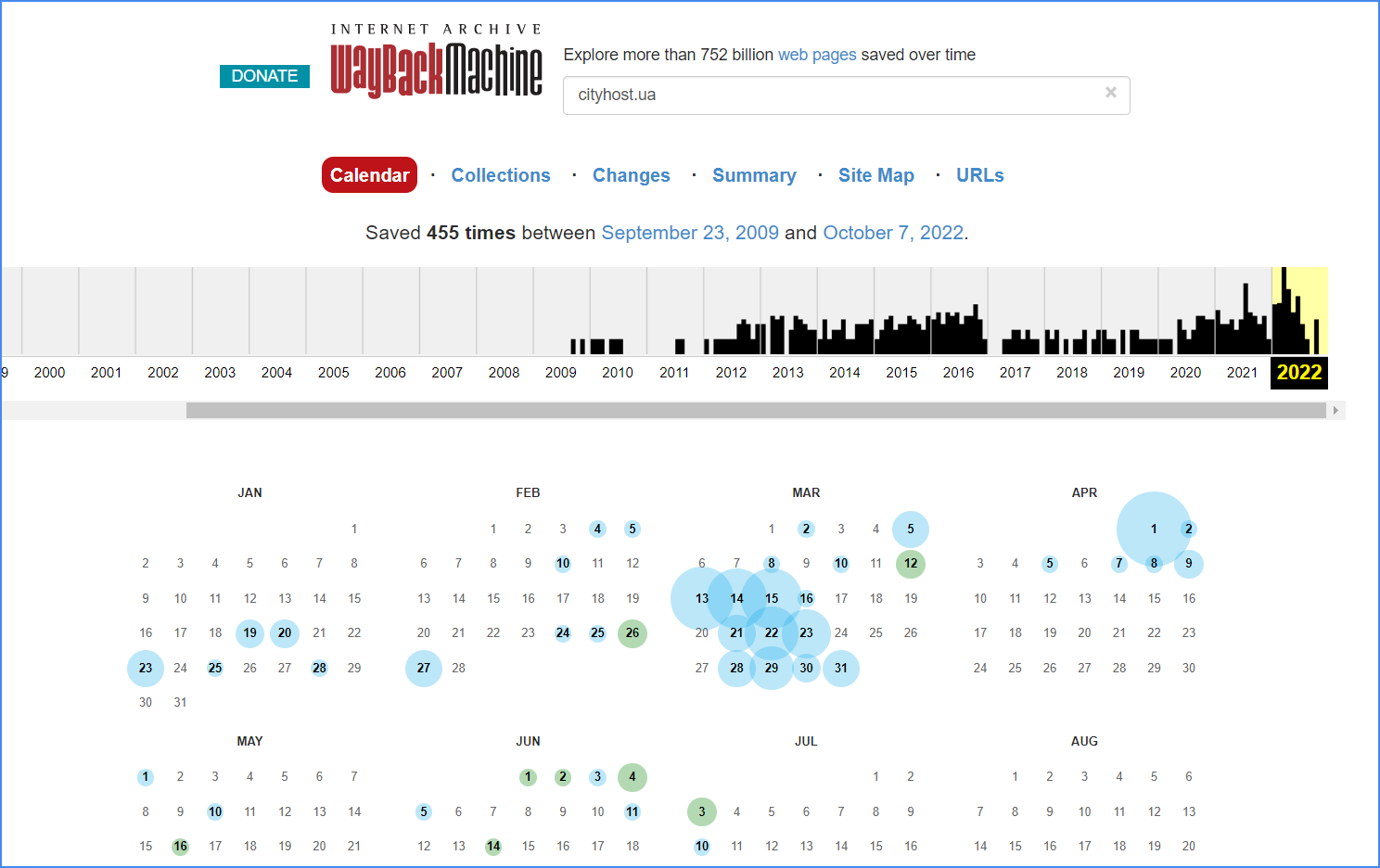
Вверху вы увидите график активности краулера, построенный на основе количества снапшотов. Ниже следует календарь, в котором эти снапшоты зафиксированы. Посмотреть состояние сайта можно только за те даты, которые отмечены синими и зелеными кружочками – именно за эти дни сохранены снимки сайта. Далее выбираете один из снапшотов, кликаете по нему, и перед вами открывается соответствующая версия сайта.
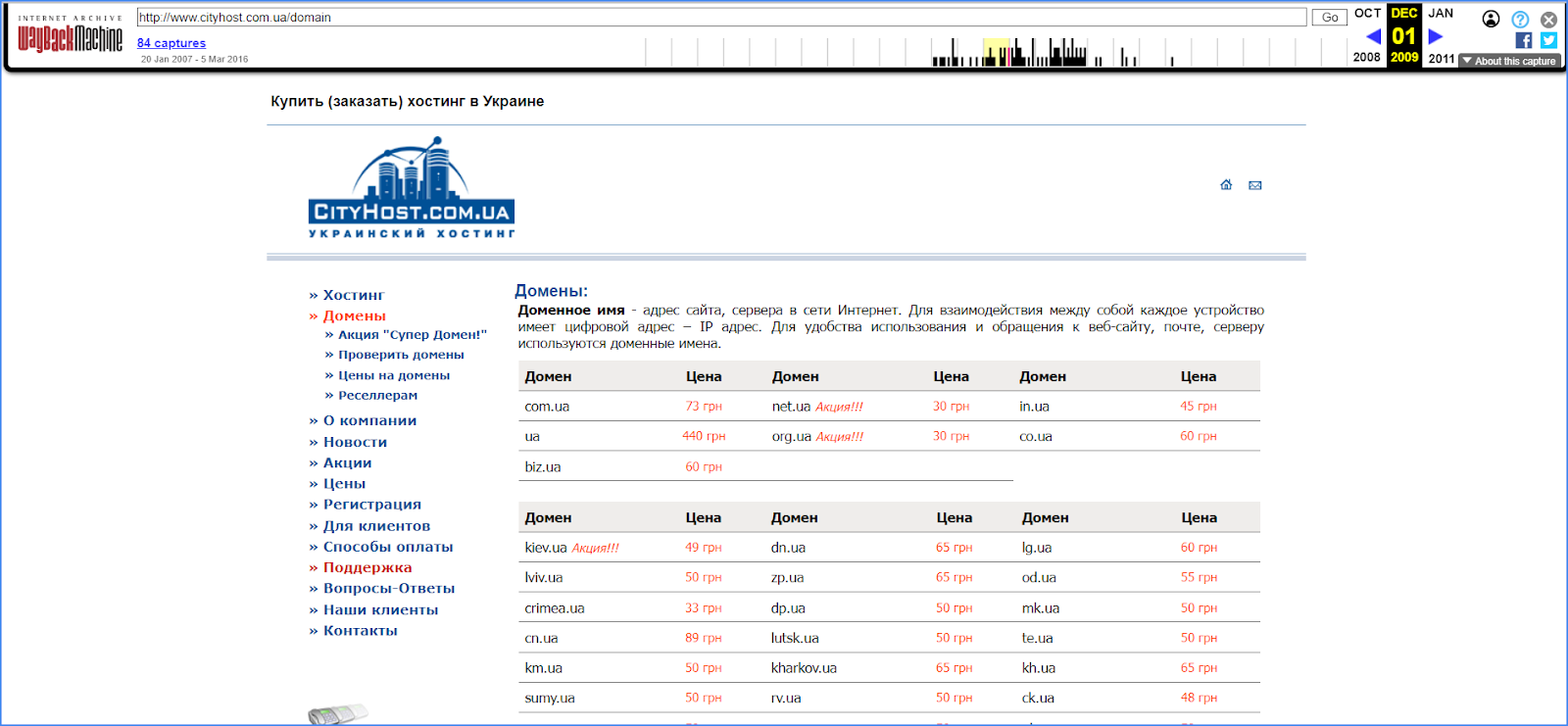
Все ссылки из меню в веб-архиве работают, так что вы можете погулять по всему сайту и увидеть все разделы. Вот такой вид, например, имел сайт Cityhost.ua в далеком 2009 году.
Читайте также: «Размещаем сайт в Интернете — какие услуги покупать и сколько они стоят»
Кроме домена, в поисковую строку можно вводить и ключевое слово – тогда вы получите список продвигаемых по этому ключу сайтов.
Другие разделы Internet Archive
Команда интернет-архива решила хранить не только сайты, но и «культурные артефакты в цифровой форме», я они это сами называют. Это отдельные файлы, в которых содержится ценный контент – видео, фото, тексты, аудио.
Web archive – это лишь часть проекта. Кроме него на сайте Internet archive есть еще 5 разделов:
-
Тексты
-
Видео
-
Аудио
-
Софт
-
Изображения
В интернет-архиве можно найти множество аудиокниг (в основном на английском языке), записи с радиостанций, документальные видео, архивы газет, выпуски новостей, художественные фильмы, музыку, старые программы и игры.
Например, вот такие интересные раритеты удалось найти в «дебрях» архива:
-
Отчет NASA за 1977 год (запуск шаттла и Вояджеров)
-
Аудиозапись джазового концерта для радио
-
Super Mario 1994 (можно поиграть прямо на сайте)
Мы специально подобрали радикально разные образцы, чтобы показать все разнообразие материала, хранящегося в интернет-архиве.
Но не обязательно все размещенные в нем файлы старые — есть много и нового контента, который архивируется прямо сейчас. Когда-то и он станет историческим достоянием.
В настоящее время в интернет-архиве насчитывается:
-
38 миллионов книг и текстов
-
4 миллиона изображений
-
790 000 программ
-
14 миллионов аудиозаписей (включая 240 000 живых концертов)
-
7 миллионов видео (включая 2 миллиона программ телевизионных новостей)
Все это богатство способно помочь не только специалистам из IT-сферы, но и любой другой отрасли найти необходимую информацию. Многие из этих файлов открыто доступны только в интернет-архиве, что превращает его в уникальную коллекцию цифровых данных.