
- What is a Search Engine Robot and How Does It Work
- What Are Search Engine Robots
- Why Should a Website Owner Know About Search Engine Robots
- How to Manage Search Engine Robots: The Robots.txt File and Other Tools
Large server load, the absence of target pages in search results, and the presence of unnecessary ones — just some of the difficulties arising from a lack of understanding of how search engines function. They use special programs to scan websites in order to provide relevant links to user queries. By knowing what a robot is and how to guide it in the right direction, you can not only avoid common problems but also improve indexing speed, optimize your website for mobile devices, quickly identify and fix technical issues, thereby enhancing SEO and increasing traffic!
Read also: Bad bots: how they harm the site and how to block them
What is a Search Engine Robot and How Does It Work
A search engine robot (web spider, crawler) is software that search engines use to gather information about a website. The web spider first visits a page and scans its content, then transmits the information to a database like Google’s (or Bing’s, Yahoo!’s). Based on the collected data, the search engine responds to user queries by providing the most relevant answers and ranking them according to specific criteria.
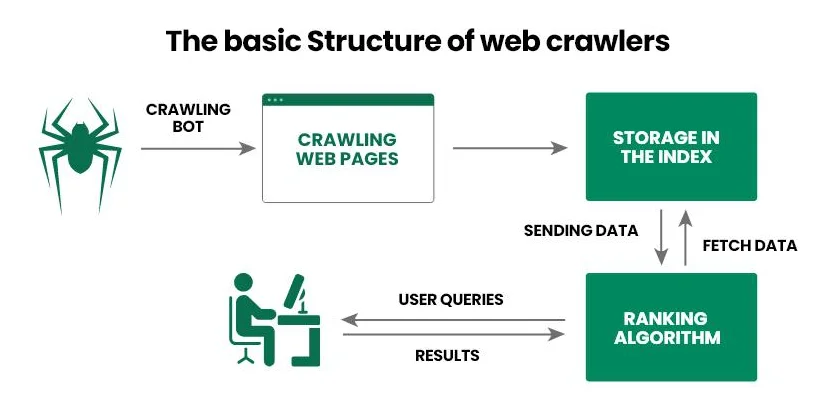
Let’s break down how a search engine robot functions step by step:
- The operator provides the crawler with an initial set of URLs, such as a list of links to popular internet projects.
- The web spider follows the links, analyzes the HTML code of the document (metadata, text, images, etc.), and other links (internal and external). Moreover, modern spiders can also process JavaScript, allowing them to scan dynamic content.
- The search engine transfers the gathered information to a database (index) for further detailed analysis and storage.
- The search engine determines the relevance of a page for specific queries and assigns it a ranking, which then influences its position in search results.
- After the information on an already indexed page is updated, the web spider returns to it, records the changes, and transmits the updated data back to the database.
Read also: What is robots.txt and how to configure robots.txt for WordPress
The main task of a search engine robot is to scan a web page for further indexing by the search engine. This ensures that search engines always have up-to-date information about the content of a website, users quickly receive answers to their queries, and website owners understand what needs to be improved to rank their web pages higher in search results.

What Are Search Engine Robots
Major search engines have their own web spiders, which they use to scan web pages and index content. By knowing these robots, you can either block their access to your website or gain access to tools to speed up indexing.
The most well-known search engine robots include:
- Googlebot. Used by the Google search engine. There are two separate crawlers: Desktop, which scans the desktop version of a site, and Mobile, which scans the mobile version.
- Bingbot. Helps the Bing search engine gather up-to-date information about websites and perform ranking based on its own algorithms.
- Slurp Bot. Used by Yahoo! to simplify the generation of search results in its search engine.
- DuckDuckBot. The web spider of DuckDuckGo, which pays special attention to user privacy when scanning websites.
- Exabot. The crawler of the lesser-known French search engine Exalead, designed to scan and index sites according to its own rules.
Among Ukrainian webmasters, Googlebot is the most well-known, and it can be managed using Google Search Console (we will discuss this process in more detail later). Owners of English-language websites also focus on Googlebot, as well as Bingbot and Slurp Bot, due to the high demand for the Bing and Yahoo! search engines.
Why Should a Website Owner Know About Search Engine Robots
While reading this material, you might think, "There are different search engine robots, they do their job well, but why do I need to know about them?" Understanding how web spiders work and knowing the most well-known ones allows you to directly influence the effectiveness of your site's promotion in search results. You can block certain crawlers from accessing your resource, optimize your documents, improve the structure of your website, inform the web scanner about updates or the addition of a new page. This way, you can speed up indexing and increase the chances of achieving a better position in search results, thereby increasing the number of targeted visitors.
Let’s look at how knowledge about search engine robots can be used in SEO:
- Optimize the robots.txt file. Software follows instructions not only from the search engine but also from the website owner. It uses robots.txt, a file that specifies which pages can be scanned and which should be ignored.
- Avoid duplicates. Sometimes duplicate content may appear on your site, confusing search engine robots and lowering your ranking in search results. To solve this issue, you can use canonical tags and redirects.
- Implement internal linking. Search engine robots pay close attention to internal and external links. You can use this information, for example, by linking old and new articles. When new pages have internal links from already indexed ones, it helps speed up their review.
- Set up a sitemap. We recommend using two sitemaps — one for search engine robots (sitemap.xml, submitted through webmaster tools) and one for users (sitemap.html). Although the latter is intended for visitors, it can also help crawlers since, as you recall, when analyzing a page, they follow all open links.
- Increase authority. Web spiders prefer domain names with a good history. You can use this to your advantage by building a link-building strategy to get links from authoritative websites, thereby increasing the authority of your site.
- Fix technical errors. One of the tasks of a website owner is to ensure that search engine robots have free access to pages. To do this, you should monitor 404 and 500 errors, redirect issues, broken links, unoptimized scripts, and styles.
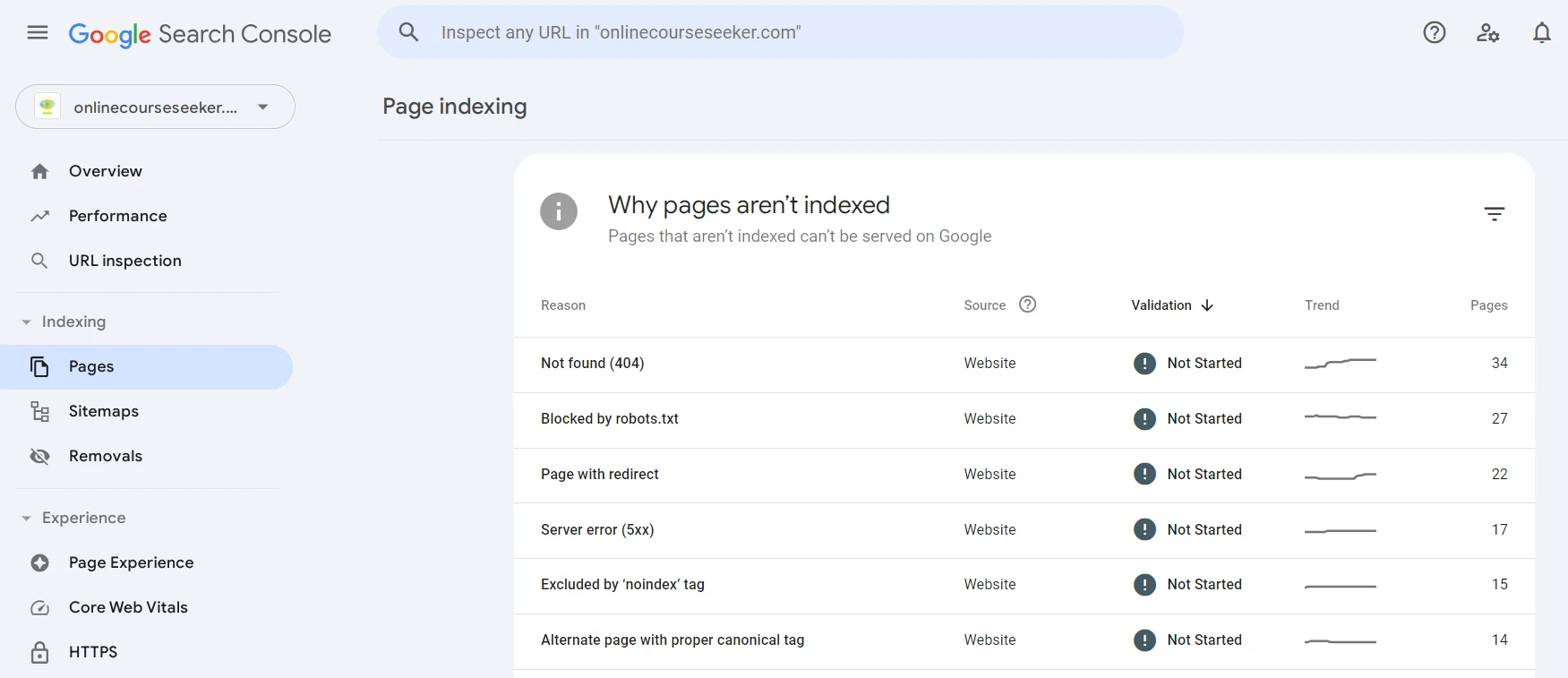
You can find pages that failed to be indexed in Google Search Console under the "Pages" section. You can explore any existing issue (Not found, Page with redirect, Excluded by ‘noindex’ tag, etc.), learn more about it, and find a list of pages that weren’t indexed because of it.
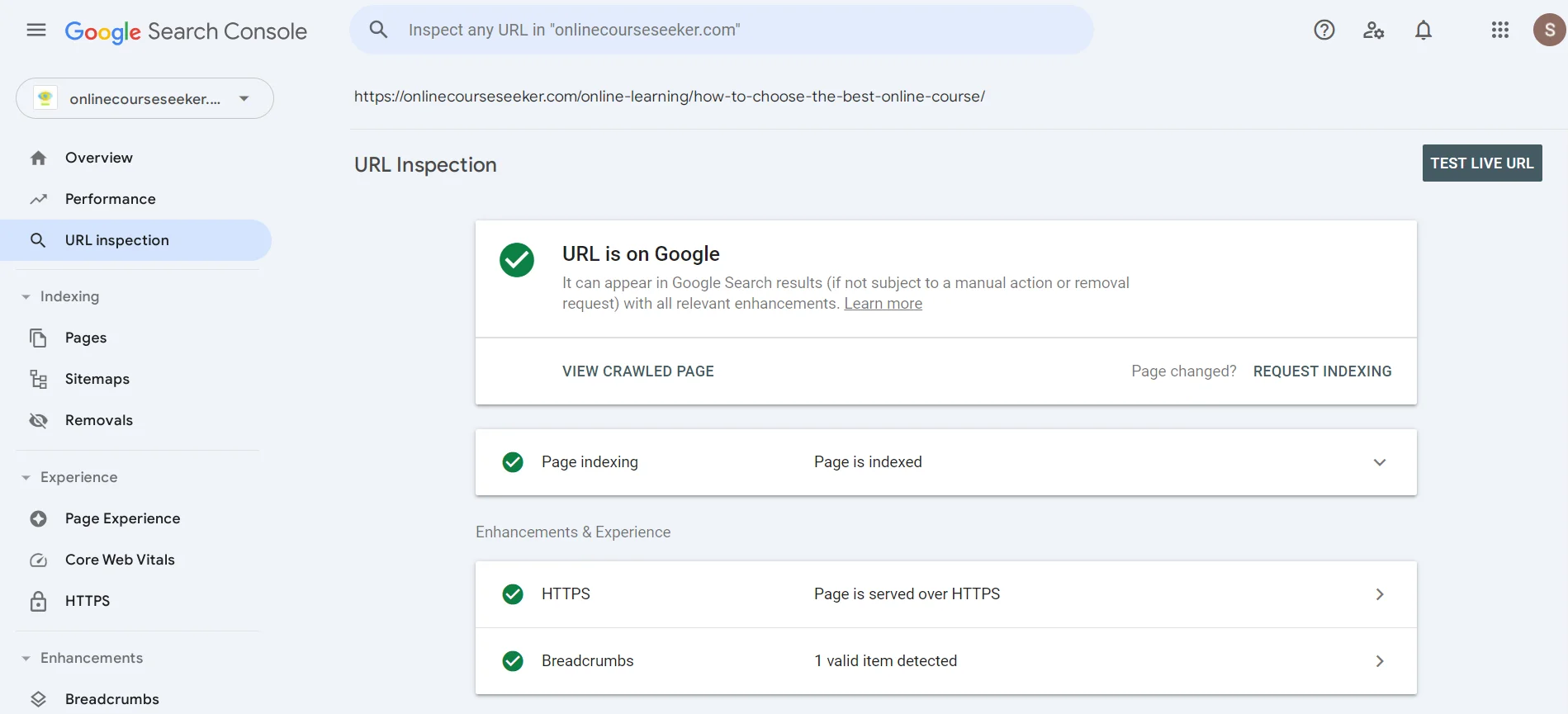
In the search bar, you can enter a URL to see if a search engine robot has already analyzed the page. If you see a message indicating that it hasn't been indexed, you can click "Request Indexing", which sends a message to the crawler, prompting it to soon take a look at your page.
Read also: How to Build a Strong Link Profile for Your Website in 2024
How to Manage Search Engine Robots: The Robots.txt File and Other Tools
The robots.txt file is a text file used to manage search engine robots' access to different parts of a website. You can create it using a simple text editor like Notepad and add it to the root directory of your website through the hosting control panel or an FTP client.
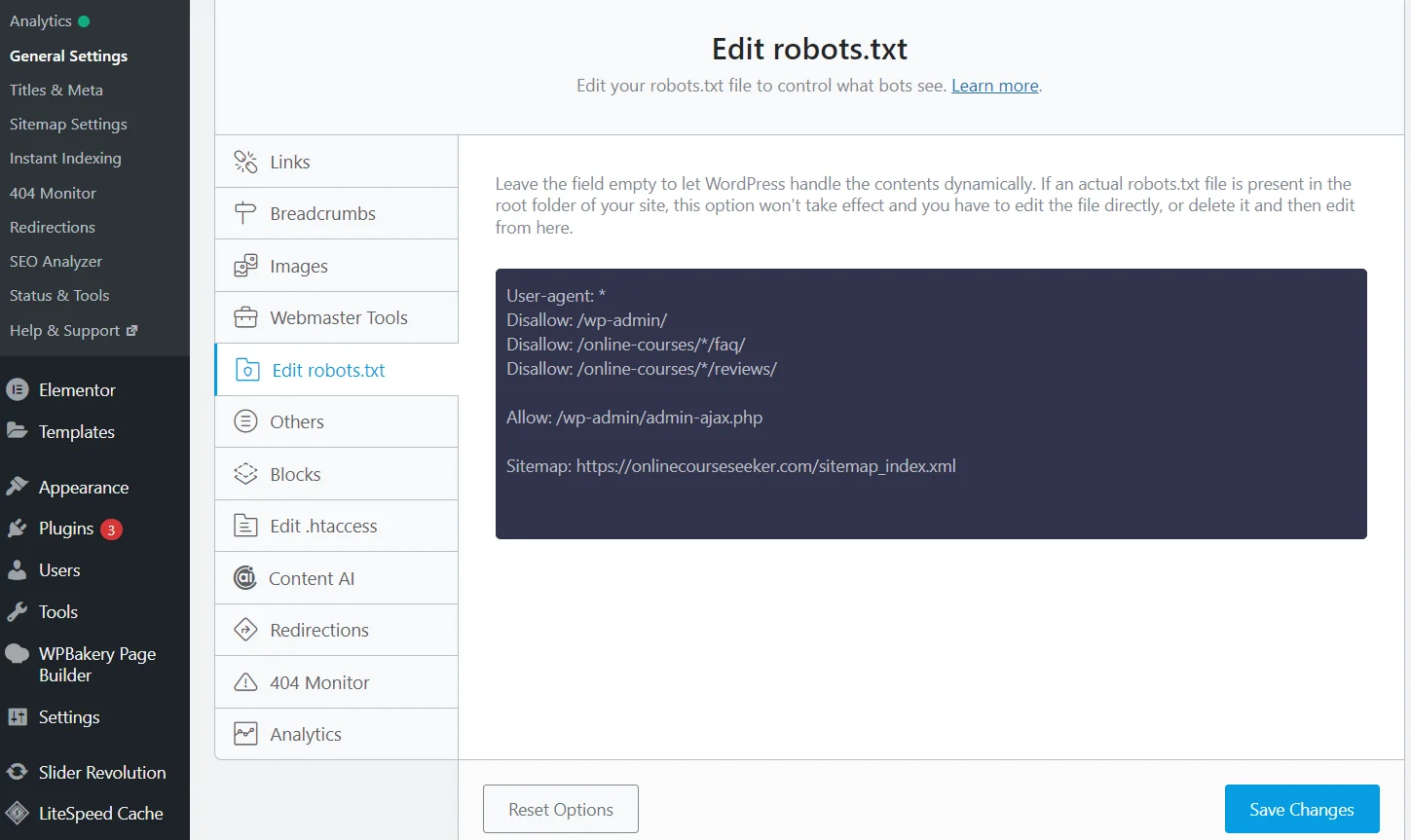
Editing Robots.txt with the Rank Math SEO Plugin
However, there is a much easier way — using SEO plugins. Simply install and activate the Rank Math plugin (Yoast, All in One, or another), and the system will create a robots.txt file for you. Moreover, it will automatically update it, and you can edit the data directly on your website without needing to access the hosting control panel.
You can use specific rules to prevent the scanning of certain pages or directories:
- Specific Page. For example, if you want to block a page for clients `https://example.com/private-page`, add the following rule to robots.txt:
User-agent: *
Disallow: /private-page
- Entire Directory. To block the scanning of an entire directory, for example, `https://example.com/private/`, use the following code:
User-agent: *
Disallow: /private/
- File Type. To block search engine robots from accessing certain file types, such as .pdf, use the following rule:
User-agent: *
Disallow: /*.pdf$
Important. While robots.txt contains a set of rules, search engine robots may not always follow them. To ensure a page is not indexed, it is recommended to also add a `noindex` meta tag to the HTML code of the page:
meta name="robots" content="noindex"
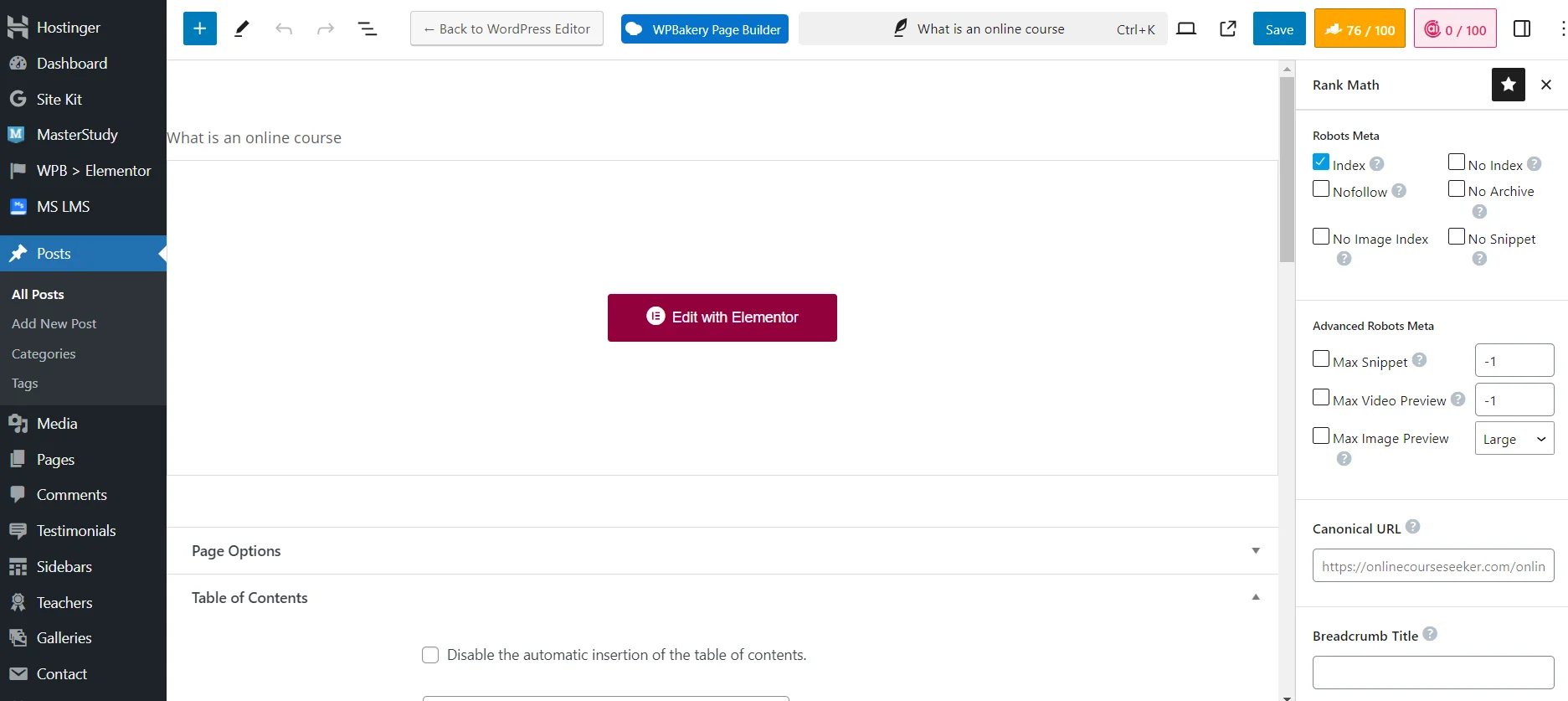
Setting Page Visibility for Search Engine Robots with Rank Math SEO Plugin
It’s much easier to prevent pages from being indexed using an SEO plugin. Simply use the necessary technical settings when adding or editing a page. For example, you can select `No Index` to fully block the content from search engine robots, or `No Image Index` to block only the image from being indexed.
Search engine robots are essential programs that significantly simplify the functioning of search engines by allowing them to quickly find and rank websites. If you optimize the robots.txt file, resolve technical issues, set up sitemaps, and implement internal linking, you can make it easier for crawlers to access the necessary parts of your website. This, in turn, will improve the ranking of these pages in search results, ultimately increasing the number of targeted visitors!








