For more than 20 years, information from all sites that exist on the network has been archived and stored in public access. The web archive of sites is an opportunity to travel through time and find out what content was posted on sites at different periods of their existence. This information is not only necessary for work, but also just interesting. Agree, would you like to know what Google or Facebook looked like at the beginning of their journey? Any Internet user can do this.
In this article, we will tell you how to find out the history of the site from the web archive, what the project itself is, where it came from and who created it.
History of the creation of the Wayback Machine
In the late 1990s, two inventors, Brewster Kale and Bruce Gilliat, thought about the problem of preserving digital content posted on websites. If the owner of the web resource does not have money to pay for the domain or is simply not interested in further support of the site, all the materials posted on it simply disappear. While newspapers, books or films are archived and stored, the Internet space has become the only source of information that is available only in real time.
In 2001, they created the non-profit organization Internet Archive with very serious intentions — to archive the entire Internet. A project to search and save web pages was launched earlier, in 1996, and was called the Wayback Machine — by analogy with a time machine.
In five years of work, by the time of the official opening, the project had already accumulated more than ten billion pages. And in 2020, the web archive of sites contained 70 petabytes of data (one petabyte is 1024 terabytes). It currently hosts 625 billion web pages on its dedicated servers .

What you can use the web archive for
This interesting tool is primarily needed for those who work with sites.
The search robot of the web archive periodically accesses the pages of the web resource and stores all site materials.
The number of scans of the Wayback Machine crawler is not directly related to updates on the site, but occurs on its own schedule.
Such archives have practical utility in many different cases.
When buying a domain
When registering a domain, you cannot know whether it is new or has already been used by someone. And only a check of its history in the web archive can show if anything has been posted on it before. This information is important for several reasons. Google "loves" old domains - it is easier to promote them in search results than new ones. If you got such an address, then this situation can be used to the maximum to promote the site. But there may be a "dark" side to a domain that had other owners before that. Therefore, it is important not only how long ago the domain was created, but also what exactly was placed on it.
Often, webmasters purposefully look for drop domains (with history) in order to promote the site faster. Before registering such an address, many different nuances are checked, including the history of the site's content.
To post affiliate links
By developing a link profile, link builders negotiate with various platforms to place links on their site. It often works as a link exchange.
The reputation of the web resource with which cooperation is planned is of great importance. For this, its link profile, organic traffic, domain age and site history are checked. Cooperation with old sites that have been developed for many years at the same address is highly valued. Links from such donors are perceived by Google as high-quality. And vice versa — links from sites with a dubious history can only harm the link profile.
To find deleted content
If the content is removed from the site, there is a high probability that it can be restored from the web archive. The reasons for such a need can be very different — from finding accidentally deleted content of your own site (although it is better to create backup copies for this) to articles on other people's sites that may be needed to confirm the publication of information (for example, you need to prove the fact of news publication).
In this way, it is possible not only to find a separate page, but also to restore the entire site.
To study the history of the development of IT technologies
Developers, web designers, copywriters, illustrators of sites need to understand how the Internet and individual web resources have changed and developed. The Wayback Machine is an inexhaustible source for studying sites from different years of their existence using living examples. This is really the case when you can get into a time machine and see everything with your own eyes.
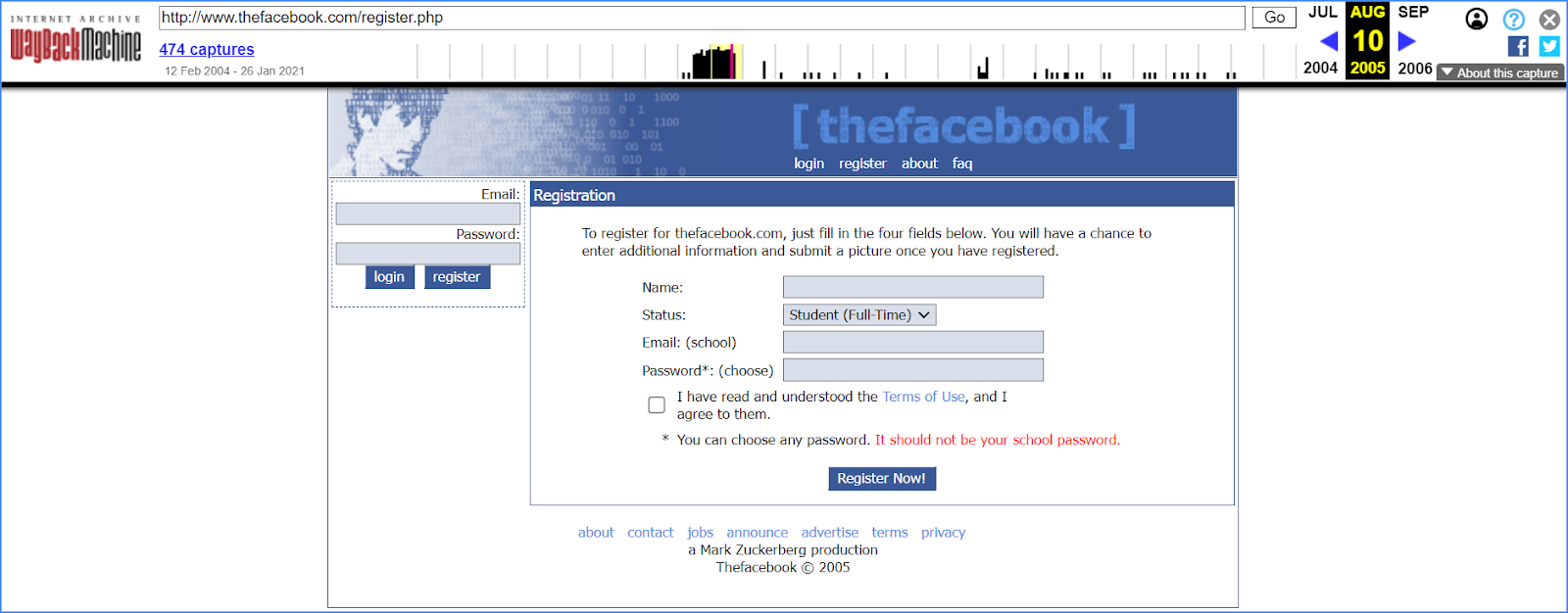 For example, with the help of the Web Archive, we can learn what Facebook looked like when it was a network for students in 2005, and no one even knew that it would turn into a business with billions of profits.
For example, with the help of the Web Archive, we can learn what Facebook looked like when it was a network for students in 2005, and no one even knew that it would turn into a business with billions of profits.
The archive of sites can also tell something else - until 2005, a site on the facebook.com domain offered to buy AboutFace software, which aimed to help companies create employee phone directories. The main feature of such electronic directories was the presence of not only contacts, but also a person's photo. As you can see, the features of the future social network can already be seen in this project.
But there is a discrepancy: in all sources, the date of foundation of the social network is indicated in 2004, but its interface appears on the domain only in 2005. The answer is simple - in its first year, the startup was hosted on the facebook.com domain. It still exists and redirects to the main address.
As you can see, you can learn a lot about the history of the site by studying it in the web archive.
Read also: " How to draw in Midjourney: Neural network generates images based on text requests ".
Wayback Machine - how to use the site archive
Follow the link to the Web Archive site . Next, you need to enter the site address in the search bar, and the service will display all the statistics.
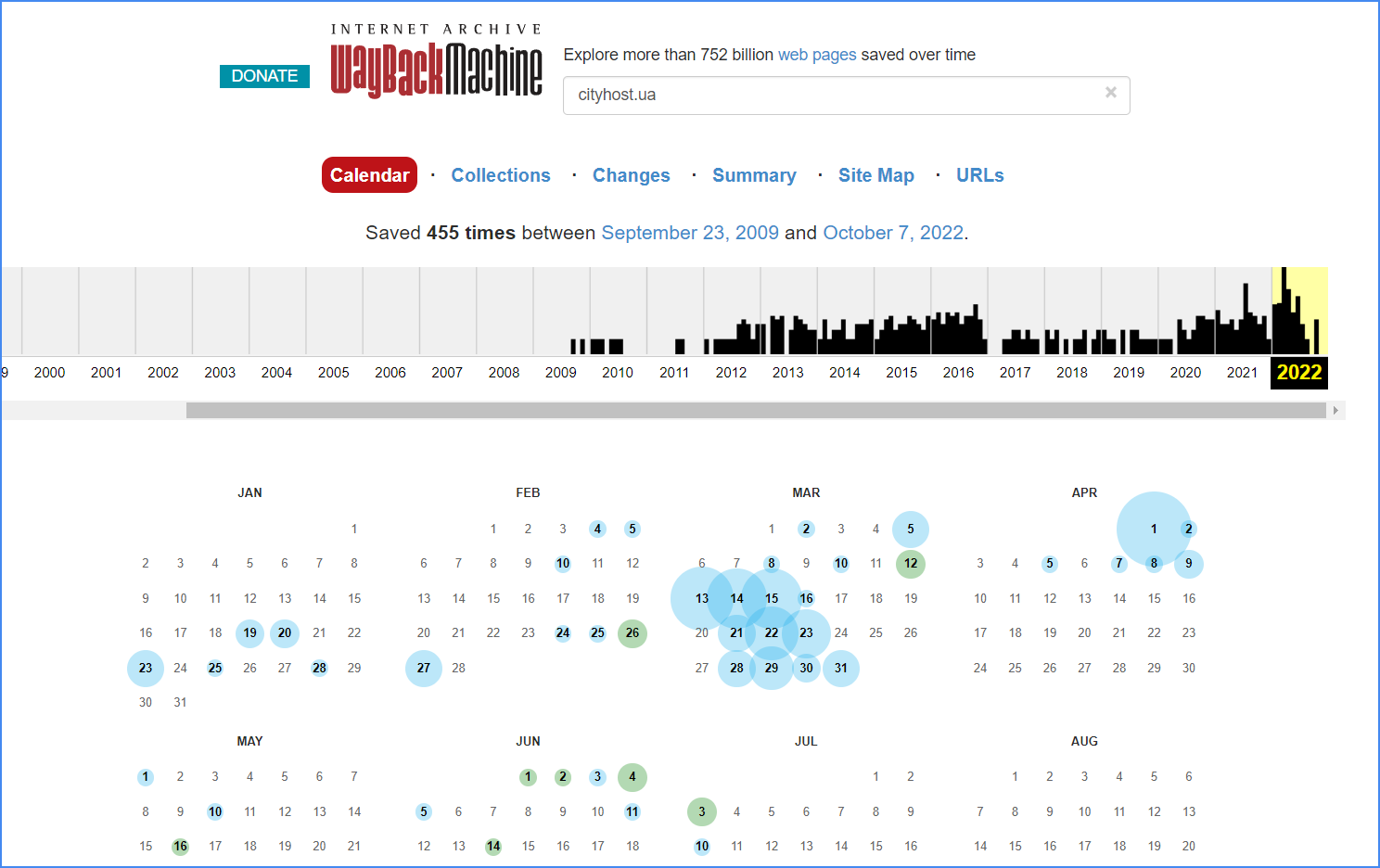
Above you will see a graph of crawler activity based on the number of snapshots. Below will be the calendar in which these snapshots are recorded. You can see the state of the site only for those dates marked with blue and green circles - it is for these days that the site snapshots are saved. Next, select one of the snapshots, click on it, and the corresponding version of the site opens in front of you.
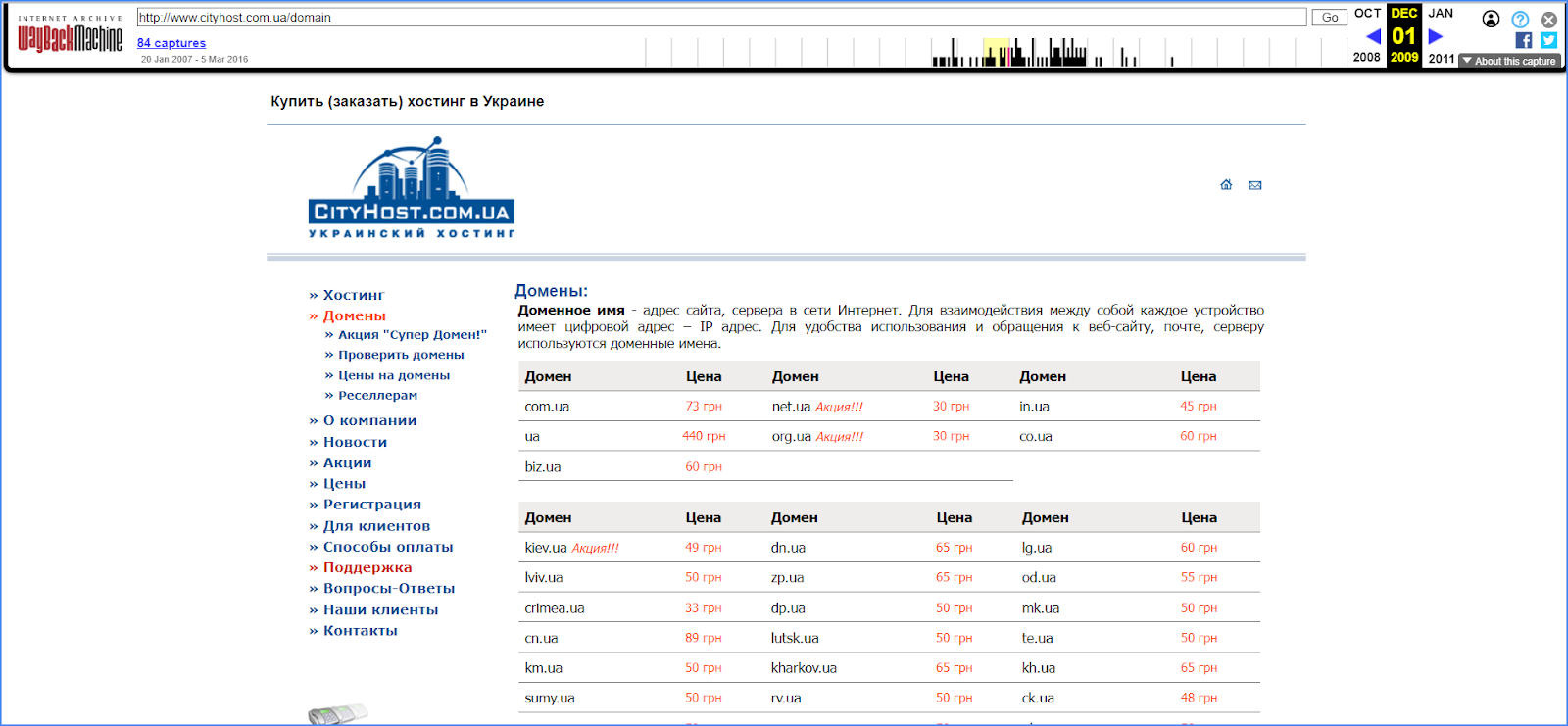
All the menu links in the web archive work, so you can walk around the site and see all the sections. This is how the Cityhost.ua site looked, for example, back in 2009.
Read also: " Placing a website on the Internet - what services to buy and how much they cost "
In addition to the domain, you can also enter a keyword in the search bar - then you will receive a list of sites that are promoted by this keyword.
Other sections of the Internet Archive
The Internet Archive team decided to preserve not only sites, but also "cultural artifacts in digital form", as they call it. These are separate files that contain valuable content — videos, photos, texts, audio.
Web archive is only part of the project. In addition to it, there are 5 more sections on the Internet archive website:
-
Lyrics
-
Video
-
audio
-
Soft
-
Image
The Internet Archive contains many audiobooks (mostly in English), radio recordings, video documentaries, newspaper archives, newscasts, feature films, music, old programs and games.
For example, it was possible to find such interesting rarities in the slums of the archive:
-
1977 NASA Report (Shuttle and Voyager Launches)
-
Audio recording of a jazz concert for the radio
-
Super Mario 1994 (you can play directly on the site)
We specifically selected radically different samples to show all the diversity of material stored in the Internet Archive.
But not necessarily all the files placed in it are old — there is a lot of new content that is being archived just now. Someday it will also become a historical property.
Currently, the Internet archive includes:
-
38 million books and texts
-
4 million images
-
790,000 programs
-
14 million audio recordings (including 240,000 live concerts)
-
7 million videos (including 2 million TV news programs)
All this wealth can help not only specialists from the IT field, but also from any other field to find the necessary information. Many of these files are openly available only in the Internet Archive, which turns it into a unique collection of digital data.