
- Что такое поисковый робот и как он работает
- Какие бывают поисковые роботы
- Зачем владельцу сайта знать о поисковых роботах
- Как управлять поисковыми работами: файл robots.txt и другие инструменты
Большая нагрузка на сервер, отсутствие в выдаче целевых страниц и наличие ненужных — это лишь часть трудностей, возникающих из-за непонимания принципа функционирования поисковиков. Они используют специальные программы для сканирования сайтов, чтобы затем предоставлять релевантные ссылки на пользовательские запросы. Если знать, что такое робот и уметь направлять его в нужном направлении, удастся не только избежать распространенных проблем. Вы сможете улучшить скорость индексации, оптимизировать веб-ресурс для мобильных устройств, быстрее выявлять и устранять технические ошибки, то есть улучшить SEO и увеличить посещаемость!
Читайте также: Плохие боты: чем они вредят сайту и как их заблокировать
Что такое поисковый робот и как он работает
Поисковый робот (веб-паук, веб-сканер, краулер) — это программное обеспечение, которое поисковики используют для сбора информации о сайте. Сначала веб-паук переходит на страницу и сканирует ее содержимое, а затем передает информацию в базу данных Google (Bing, Yahoo!). А уже на основе полученных сведений поисковик отвечает на запрос пользователя: дает наиболее релевантные ответы и ранжирует их по определенным критериям.
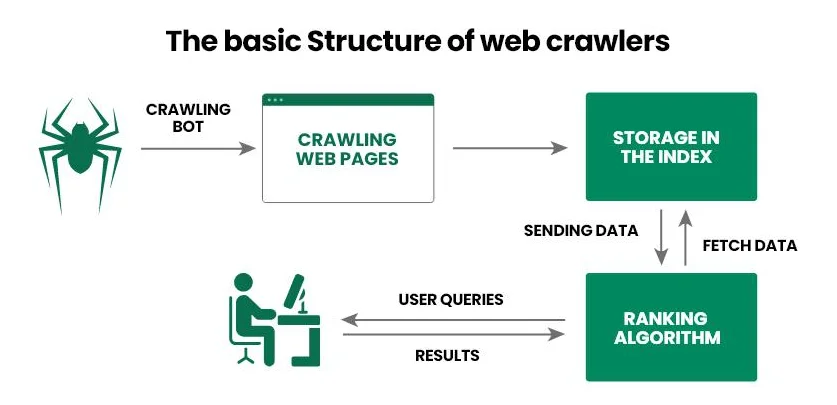
Рассмотрим принцип функционирования поискового робота шаг за шагом:
- Оператор предоставляет краулеру стартовый набор URL, например список ссылок на популярные интернет-проекты.
- Веб-паук переходит по ссылкам, анализирует HTML-код документа (метаданные, текст, изображения и т.д.) и другие ссылки (внутренние и внешние). Кроме того, современные пауки могут также обрабатывать JavaScript, что делает их способными сканировать динамический контент.
- Полученные сведения поисковик передает в базу данных (индекс) для дальнейшего детального изучения и хранения.
- Поисковик определяет релевантность страницы для конкретных запросов и присваивает ей рейтинг, от которого затем зависит позиция в выдаче.
- После обновления информации на уже проиндексированной странице, веб-паук возвращается на нее, фиксирует изменения и снова передает сведения в базу данных.
Читайте также: Что такое robots.txt и как настроить robots.txt для WordPress
Главная задача поискового робота — просканировать веб-страницу для дальнейшего индексирования поисковиком. Так у поисковых систем всегда есть актуальная информация о содержании интернет-проекта, пользователи — быстро получают ответ на свой запрос, а владельцы сайтов — понимают, что нужно улучшить, чтобы вывести веб-страницу на первые позиции в выдаче.

Какие бывают поисковые роботы
Большие поисковики имеют собственных веб-пауков, которых используют для сканирования веб-страниц и индексации контента. Зная этих роботов, вы можете заблокировать им доступ к своему веб-ресурсу или, наоборот, получить доступ к инструментам для ускорения индексации.
Наиболее известными являются следующие поисковые роботы:
- Googlebot. Используется поисковиком Google. Есть два отдельных краулера: Desktop сканирует компьютерную версию сайта, а Mobile — мобильную.
- Bingbot. Помогает поисковику Bing получать актуальную информацию о веб-ресурсах и проводить ранжирование по собственным алгоритмам.
- Slurp Bot. Используется для упрощенного формирования результатов выдачи в поисковике Yahoo!.
- DuckDuckBot. Веб-паук поисковика DuckDuckGo, который при сканировании веб-ресурса уделяет особое внимание защите пользователей.
- Exabot. Краулер малоизвестной французской поисковой системы Exalead, предназначенный для сканирования и индексации сайтов по собственным правилам.
Среди украинских веб-мастеров наиболее известен Googlebot, которым можно управлять с помощью Google Search Console (далее мы подробнее рассмотрим этот процесс). Владельцы англоязычных интернет-проектов делают ставку не только на Googlebot, но и на Bingbot и Slurp Bot, что объясняется большим спросом на поисковые системы Bing и Yahoo!
Читайте также: SEO на минималках – что владелец сайта может сделать самостоятельно для продвижения сайта без привлечения специалистов
Зачем владельцу сайта знать о поисковых роботах
Читая материал, вы могли подумать: «Есть разные поисковые роботы, они хорошо выполняют свои задачи, но зачем мне вообще о них знать». Понимание принципа функционирования веб-пауков и знание наиболее известных из них позволяет оказывать непосредственное влияние на эффективность продвижения сайта в выдаче. Вы можете запретить определенным краулерам доступ к ресурсу, оптимизировать документ, улучшить структуру интернет-проекта, сообщить веб-сканеру об обновлении информации или добавлении новой страницы. Так вы сможете ускорить индексацию и повысить шансы на получение лучшей позиции в выдаче, соответственно увеличить количество целевых посетителей.
Разберем, как использовать знания о поисковых роботах в SEO:
- Оптимизировать файл robots.txt. Программное обеспечение следует инструкциям не только поисковой системы, но и владельца веб-ресурса. Для этого оно использует robots.txt — файл, где указано, какие страницы можно сканировать, а какие нужно игнорировать.
- Избегать дубликатов. Иногда на сайте могут возникать дубликаты контента, запутывающего поисковых роботов, соответственно снижает позиции в выдаче. Для решения проблемы можно использовать канонические теги и редиректы (перенаправление).
- Делать перелинковку. Поисковые роботы уделяют большое внимание внутренним и внешним ссылкам. Вы можете использовать эту информацию, например, связать ссылками старые и новые статьи. Когда новые страницы имеют внутренние ссылки из уже проиндексированных, это помогает ускорить их проверку.
- Настроить карту сайта. Мы рекомендуем использовать две карты сайта — для поисковых роботов (sitemap.xml, подается через инструменты для вебмастеров) и для пользователей (sitemap.html). Хотя вторая предназначена для посетителей веб-ресурса, она может помочь и краулерам, ведь, как вы помните, анализируя страницу, они переходят по всем открытым линкам.
- Повышать авторитетность. Веб-пауки предпочитают доменные имена с хорошей историей. Вы можете использовать этот момент: постройте стратегию линкбилдинга, чтобы получить ссылки из авторитетных интернет-проектов, соответственно повысить авторитетность своего сайта.
- Устранять технические ошибки. Одна из задач владельца веб-ресурса — обеспечить поисковым роботам свободный доступ к страницам. Для этого следует отслеживать ошибки 404 и 500, проблемы с редиректами, поврежденные ссылки, не оптимизированные скрипты и стили.
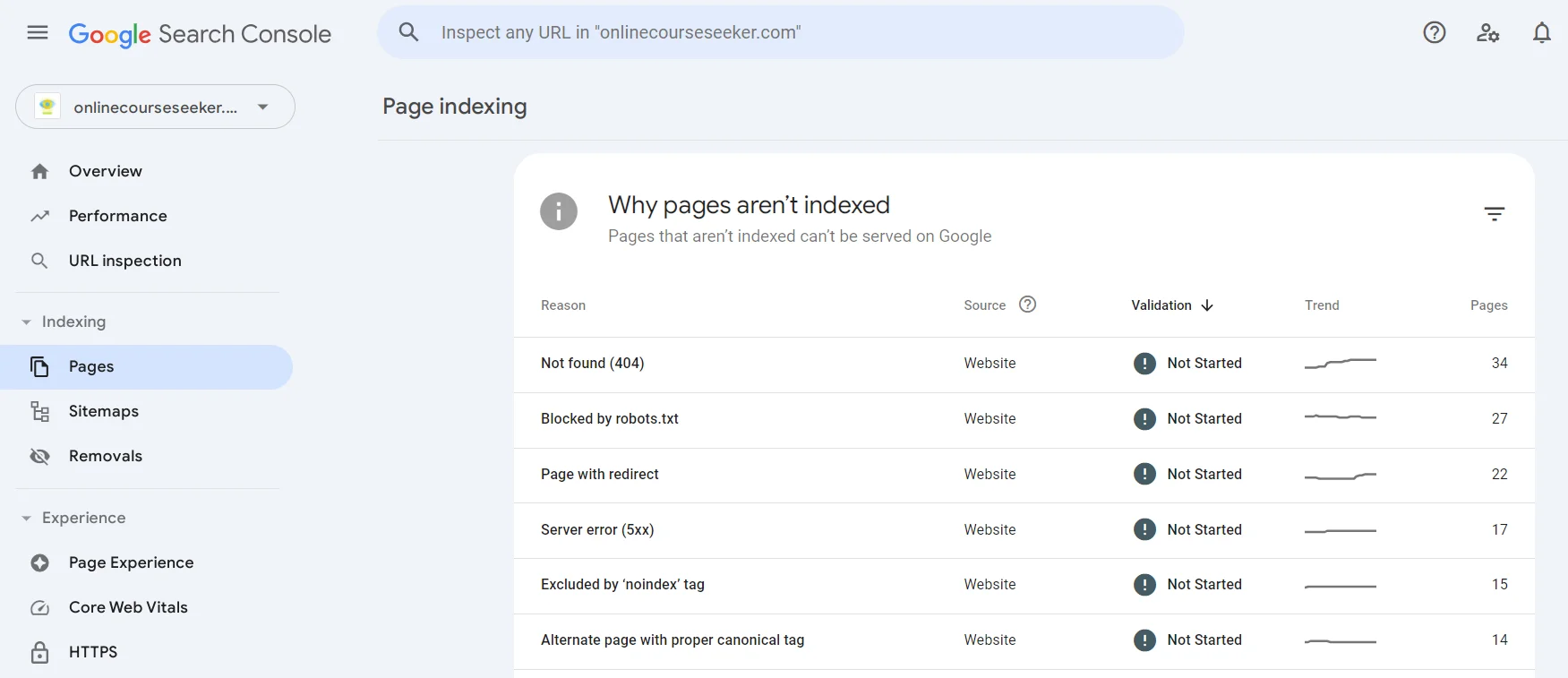
А найти страницы, которые не удалось проиндексировать, можно в Google Search Console в разделе Pages. Вы можете перейти к любой существующей проблеме (Not found, Page with redirect, Excluded by «noindex» tag и т.д.), узнать о ней больше и найти список страниц, которые через нее не были проиндексированы.
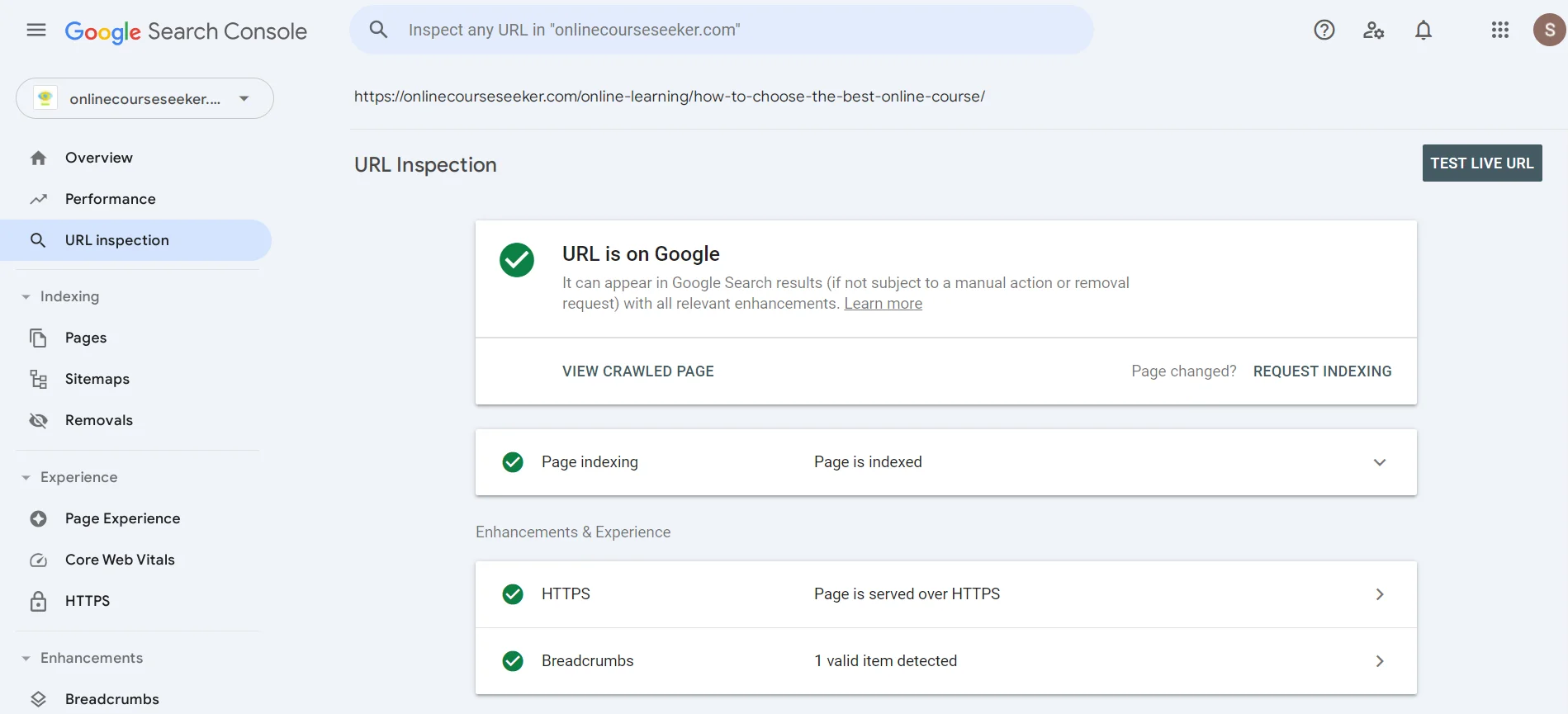
В поиске можно указать URL с целью узнать, проанализировал ли уже поисковый робот страницу. Если вы увидите сообщение об отсутствии индексации, можете нажать Request Indexing, то есть отправить краулеру сообщение, чтобы он вскоре обратил внимание на вашу страницу.
Читайте также: Как построить сильный ссылочный профиль сайта в 2024 году
Как управлять поисковыми работами: файл robots.txt и другие инструменты
Файл robots.txt — это текстовый файл для управления доступом поисковых роботов к разным частям сайта. Его можно создать с помощью обычного текстового редактора, например Notepad, и добавить в корневую директорию веб-ресурса через панель управления хостинга или FTP-клиент.
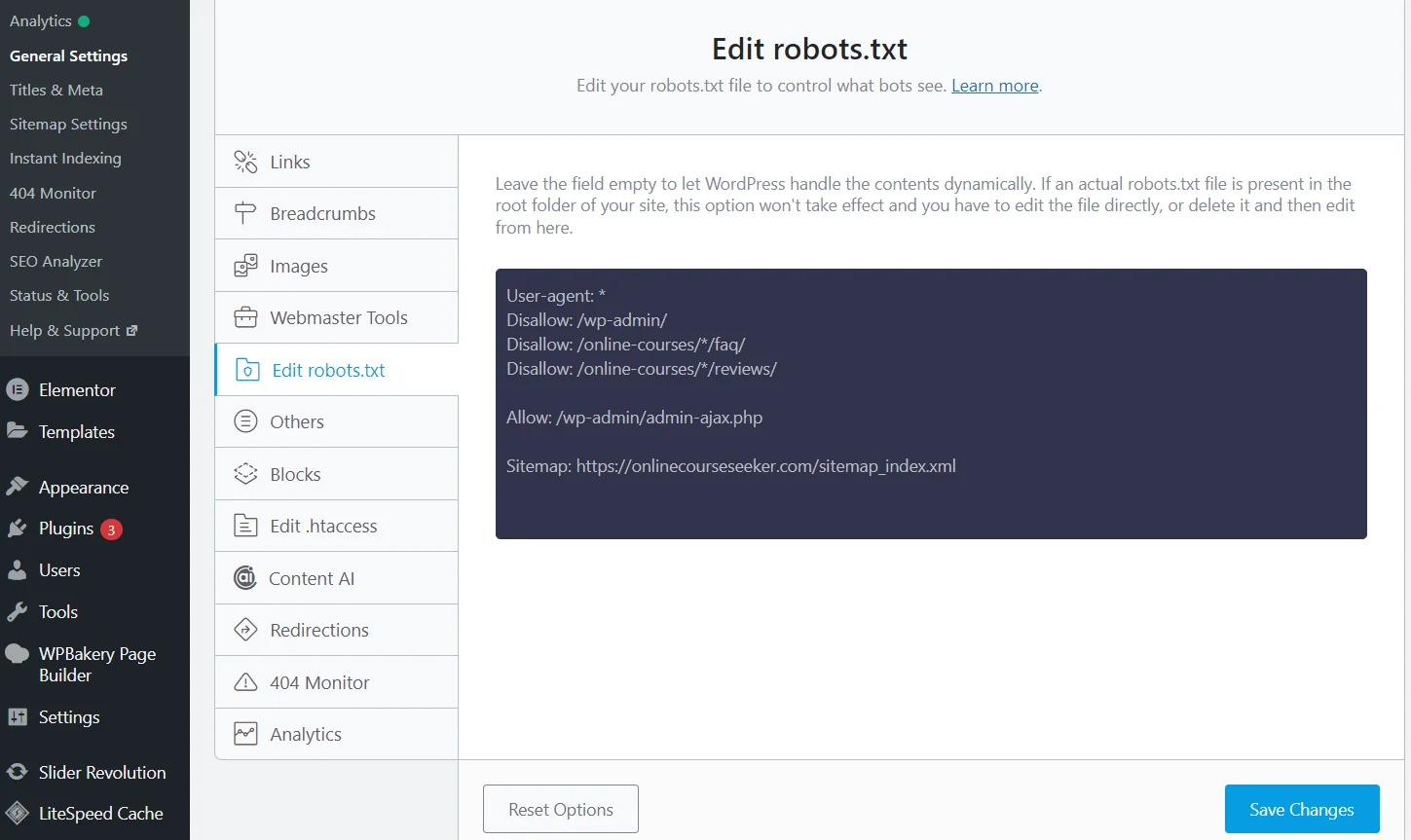
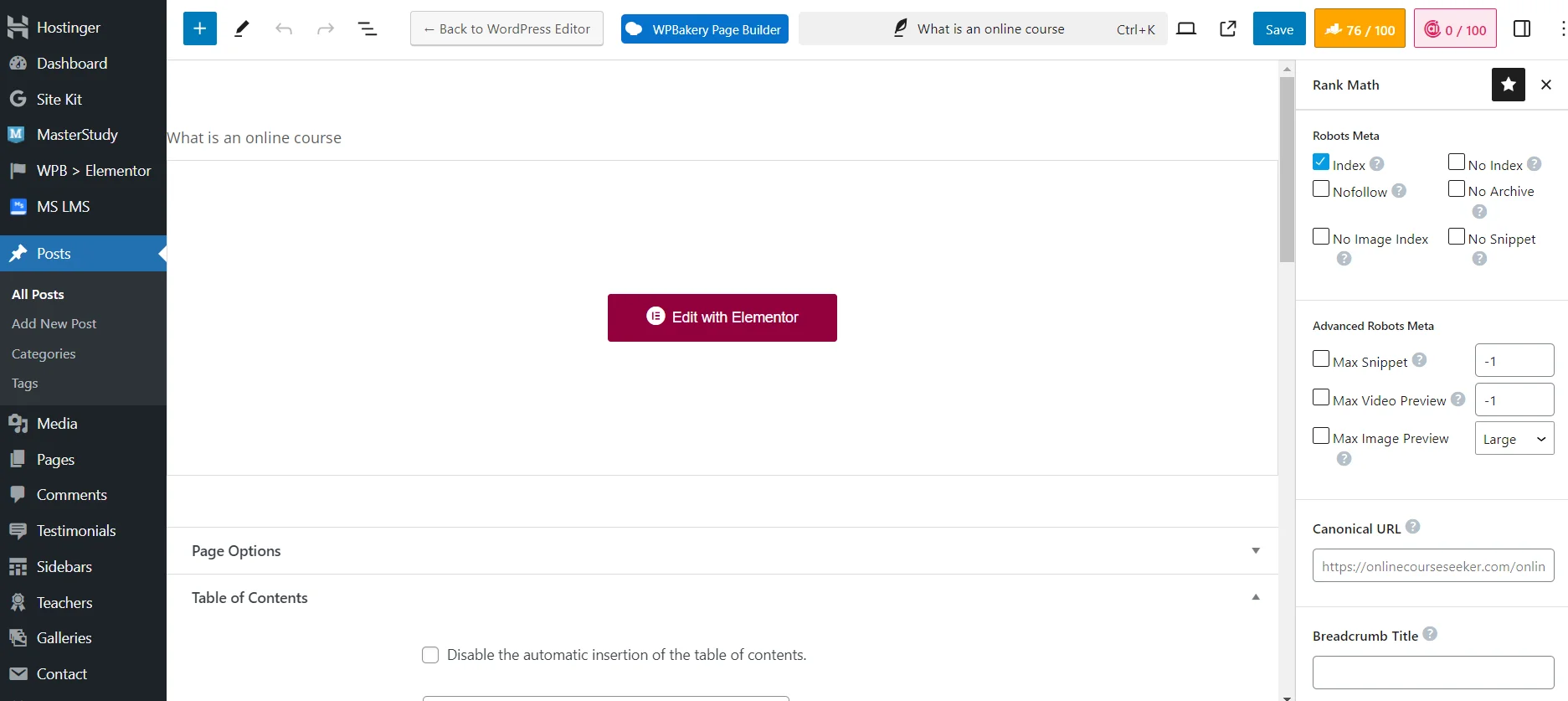
Редактирование robots.txt с плагином Rank Math SEO
Но есть гораздо более простой способ — SEO плагины. Достаточно установить и активировать плагин Rank Math (Yoast, All in One или другой), после чего система создаст файл robots.txt. К тому же она будет автоматически обновлять его, а отредактировать данные можно прямо на сайте, благодаря чему не нужно переходить в панель управления хостинга.
Вы можете использовать специальные правила, чтобы запретить сканирование определенных страниц/директорий:
- Конкретная страница. К примеру, нужно закрыть страницу для клиентов `https://example.com/private-page`. Добавьте в robots.txt правило
User-agent: *
Disallow: /private-page
- Вся директория. Запретить сканирование всей директории, например `https://example.com/private/` поможет код
User-agent: *
Disallow: /private/
- Тип файла. Закрыть от поисковых роботов определенные типы файла, например .pdf помогает правило
User-agent: *
Disallow: /*.pdf$
Важно: robots.txt содержит набор правил, но поисковые работы могут им не следовать. Чтобы точно закрыть страницу от индексации, рекомендуем дополнительно добавить метатег `noindex` в HTML-код страницы:
meta name="robots" content="noindex"
Настройка видимости страницы сайта для поисковых роботов с плагином Rank Math SEO
Хотя гораздо проще закрывать страницы от индексации через SEO плагин. Достаточно использовать необходимые технические настройки при добавлении или редактировании страницы. К примеру, можете поставить `No Index`, чтобы полностью закрыть материал от поисковых роботов. Или `No Image Index`, чтобы закрыть от индексации только изображение.
Поисковые работы — важные программы, существенно упрощающие функционирование поисковиков, позволяя им быстро находить и ранжировать сайты. Если оптимизируете файл robots.txt, решите технические проблемы, настроите карты, сделаете перелинковку, вам удастся упростить краулерам доступ к нужным частям веб-ресурса. А это позволит улучшить позиции этих страниц в поисковой выдаче, соответственно увеличить количество целевых посетителей!








