
- Was ist ein Suchmaschinen-Roboter und wie funktioniert er?
- Welche Arten von Suchmaschinen-Robotern gibt es?
- Warum sollte ein Website-Besitzer über Suchmaschinen-Roboter Bescheid wissen?
- Wie man Suchmaschinen-Roboter verwaltet: die robots.txt-Datei und andere Werkzeuge
Eine hohe Serverlast, das Fehlen von Zielseiten in den Ergebnissen und das Vorhandensein unnötiger Seiten — das sind nur einige der Schwierigkeiten, die aufgrund des Missverständnisses der Funktionsweise von Suchmaschinen auftreten. Sie verwenden spezielle Programme, um Websites zu scannen, um dann relevante Links zu den Benutzeranfragen bereitzustellen. Wenn man weiß, was ein Roboter ist und wie man ihn in die richtige Richtung lenkt, kann man nicht nur häufige Probleme vermeiden. Man kann die Geschwindigkeit der Indizierung verbessern, die Website für mobile Geräte optimieren, technische Fehler schneller identifizieren und beheben, das heißt, SEO verbessern und die Besucherzahlen erhöhen!
Lesen Sie auch: Schlechte Bots: Wie sie der Website schaden und wie man sie blockiert
Was ist ein Suchmaschinen-Roboter und wie funktioniert er?
Ein Suchmaschinen-Roboter (Web-Crawler, Web-Spider) — ist eine Software, die von Suchmaschinen verwendet wird, um Informationen über eine Website zu sammeln. Zuerst besucht der Web-Crawler die Seite und scannt ihren Inhalt, und überträgt dann die Informationen in die Datenbank von Google (Bing, Yahoo!). Basierend auf den erhaltenen Informationen beantwortet die Suchmaschine die Benutzeranfrage: Sie gibt die relevantesten Antworten und rangiert sie nach bestimmten Kriterien.
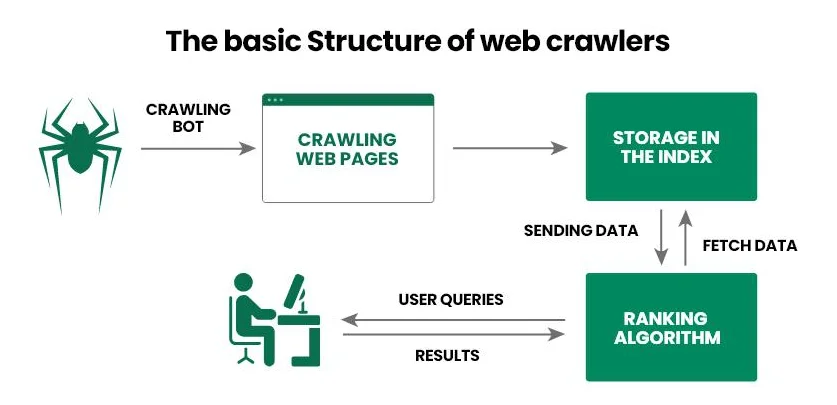
Betrachten wir das Funktionsprinzip eines Suchmaschinen-Roboters Schritt für Schritt:
- Der Betreiber stellt dem Crawler einen Start-URL-Satz zur Verfügung, zum Beispiel eine Liste von Links zu beliebten Internetprojekten.
- Der Web-Crawler folgt den Links, analysiert den HTML-Code des Dokuments (Metadaten, Text, Bilder usw.) und andere Links (interne und externe). Darüber hinaus können moderne Crawler auch JavaScript verarbeiten, was sie in die Lage versetzt, dynamische Inhalte zu scannen.
- Die erhaltenen Informationen überträgt die Suchmaschine in die Datenbank (Index) zur weiteren detaillierten Untersuchung und Speicherung.
- Die Suchmaschine bestimmt die Relevanz der Seite für bestimmte Anfragen und vergibt ihr eine Bewertung, von der dann die Position in den Ergebnissen abhängt.
- Nach der Aktualisierung der Informationen auf der bereits indizierten Seite kehrt der Web-Crawler zurück, zeichnet die Änderungen auf und überträgt die Informationen erneut in die Datenbank.
Lesen Sie auch: Was ist robots.txt und wie man robots.txt für WordPress einrichtet
Die Hauptaufgabe eines Suchmaschinen-Roboters besteht darin, eine Webseite zu scannen, um sie später von der Suchmaschine indizieren zu lassen. So haben Suchmaschinen immer aktuelle Informationen über den Inhalt des Internetprojekts, Benutzer — erhalten schnell eine Antwort auf ihre Anfrage, und Website-Besitzer — verstehen, was verbessert werden muss, um die Webseite in den oberen Positionen der Ergebnisse zu platzieren.

Welche Arten von Suchmaschinen-Robotern gibt es?
Große Suchmaschinen haben ihre eigenen Web-Crawler, die sie zum Scannen von Webseiten und zur Indizierung von Inhalten verwenden. Wenn Sie diese Roboter kennen, können Sie ihnen den Zugriff auf Ihr Webprojekt verweigern oder umgekehrt auf Werkzeuge zugreifen, um die Indizierung zu beschleunigen.
Die bekanntesten Suchmaschinen-Roboter sind:
- Googlebot. Wird von der Suchmaschine Google verwendet. Es gibt zwei separate Crawler: Desktop scannt die Computer-Version der Website, während Mobile die mobile Version scannt.
- Bingbot. Hilft der Suchmaschine Bing, aktuelle Informationen über Webressourcen zu erhalten und diese nach eigenen Algorithmen zu rangieren.
- Slurp Bot. Wird für die vereinfachte Erstellung von Suchergebnissen in der Suchmaschine Yahoo! verwendet.
- DuckDuckBot. Der Web-Crawler der Suchmaschine DuckDuckGo, der beim Scannen von Webressourcen besonderen Wert auf den Schutz der Benutzer legt.
- Exabot. Crawler der wenig bekannten französischen Suchmaschine Exalead, die zum Scannen und Indizieren von Websites nach eigenen Regeln gedacht ist.
Unter ukrainischen Webmastern ist Googlebot am bekanntesten, den man über die Google Search Console steuern kann (wir werden diesen Prozess später genauer betrachten). Besitzer englischsprachiger Internetprojekte setzen nicht nur auf Googlebot, sondern auch auf Bingbot und Slurp Bot, was durch die hohe Nachfrage nach den Suchmaschinen Bing und Yahoo! erklärt wird.
Lesen Sie auch: SEO auf Minimalniveau – was der Website-Besitzer selbst tun kann, um die Website ohne die Hinzuziehung von Spezialisten zu fördern
Warum sollte ein Website-Besitzer über Suchmaschinen-Roboter Bescheid wissen?
Beim Lesen des Materials könnten Sie gedacht haben: «Es gibt verschiedene Suchmaschinen-Roboter, sie erfüllen ihre Aufgaben gut, aber warum sollte ich überhaupt über sie Bescheid wissen?» Das Verständnis des Funktionsprinzips von Web-Crawlern und das Wissen über die bekanntesten von ihnen ermöglicht es, direkten Einfluss auf die Effektivität der Website-Promotion in den Ergebnissen zu nehmen. Sie können bestimmten Crawlern den Zugriff auf die Ressource verweigern, das Dokument optimieren, die Struktur des Internetprojekts verbessern, den Web-Crawler über Aktualisierungen oder das Hinzufügen neuer Seiten informieren. So können Sie die Indizierung beschleunigen und die Chancen auf eine bessere Position in den Ergebnissen erhöhen, was wiederum die Anzahl der zielgerichteten Besucher steigert.
Schauen wir uns an, wie man das Wissen über Suchmaschinen-Roboter im SEO nutzen kann:
- Die robots.txt-Datei optimieren. Die Software folgt nicht nur den Anweisungen der Suchmaschine, sondern auch den Anweisungen des Website-Besitzers. Dazu verwendet sie die robots.txt-Datei — eine Datei, in der angegeben ist, welche Seiten gescannt werden dürfen und welche ignoriert werden sollen.
- Duplikate vermeiden. Manchmal können auf der Website Duplikate von Inhalten entstehen, die die Suchmaschinen-Roboter verwirren und somit die Positionen in den Ergebnissen senken. Um das Problem zu lösen, können kanonische Tags und Redirects (Weiterleitungen) verwendet werden.
- Interne Verlinkungen erstellen. Suchmaschinen-Roboter legen großen Wert auf interne und externe Links. Sie können diese Information nutzen, um beispielsweise alte und neue Artikel miteinander zu verlinken. Wenn neue Seiten interne Links von bereits indizierten Seiten haben, hilft das, ihre Überprüfung zu beschleunigen.
- Die Sitemap einrichten. Wir empfehlen, zwei Sitemaps zu verwenden — eine für Suchmaschinen-Roboter (sitemap.xml, die über Webmaster-Tools eingereicht wird) und eine für Benutzer (sitemap.html). Obwohl die zweite für die Besucher der Webressource gedacht ist, kann sie auch den Crawlern helfen, denn wie Sie sich erinnern, gehen sie beim Analysieren einer Seite allen offenen Links nach.
- Die Autorität erhöhen. Web-Crawler bevorzugen Domainnamen mit einer guten Geschichte. Sie können diesen Punkt nutzen: Entwickeln Sie eine Linkbuilding-Strategie, um Links von autoritativen Internetprojekten zu erhalten und somit die Autorität Ihrer Website zu erhöhen.
- Technische Fehler beheben. Eine der Aufgaben des Website-Besitzers besteht darin, den Suchmaschinen-Robotern freien Zugang zu den Seiten zu gewähren. Dazu sollten Fehler 404 und 500, Probleme mit Redirects, defekte Links, nicht optimierte Skripte und Styles überwacht werden.
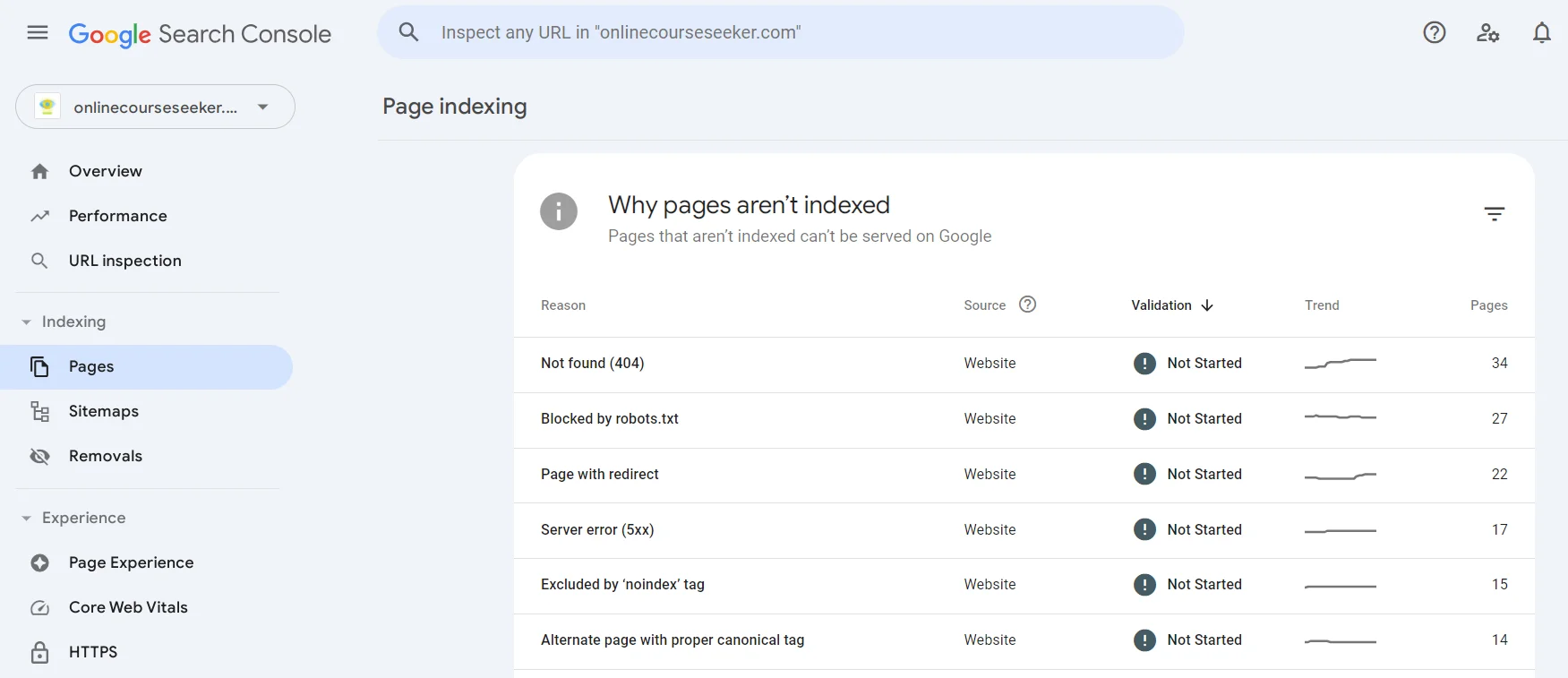
Die Seiten, die nicht indiziert werden konnten, finden Sie in der Google Search Console im Abschnitt Seiten. Sie können zu jedem bestehenden Problem (Nicht gefunden, Seite mit Weiterleitung, Ausgeschlossen durch das «noindex»-Tag usw.) wechseln, mehr darüber erfahren und eine Liste der Seiten finden, die darüber nicht indiziert wurden.
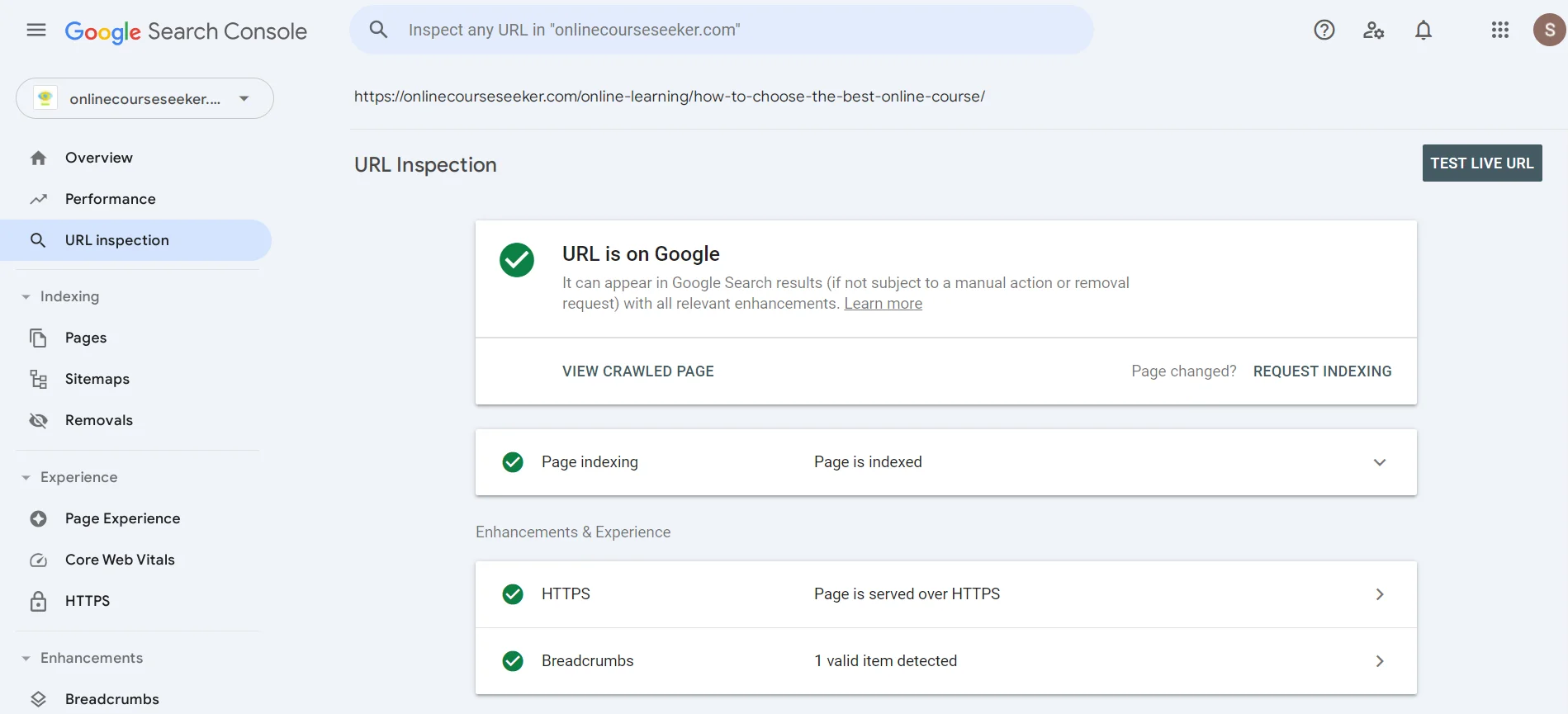
Im Suchfeld können Sie die URL angeben, um herauszufinden, ob der Suchmaschinen-Roboter die Seite bereits analysiert hat. Wenn Sie die Meldung über das Fehlen der Indizierung sehen, können Sie auf Anfrage zur Indizierung klicken, um dem Crawler eine Nachricht zu senden, dass er bald auf Ihre Seite achten soll.
Lesen Sie auch: Wie man ein starkes Linkprofil der Website im Jahr 2024 aufbaut
Wie man Suchmaschinen-Roboter verwaltet: die robots.txt-Datei und andere Werkzeuge
Die robots.txt-Datei — ist eine Textdatei zur Steuerung des Zugriffs von Suchmaschinen-Robotern auf verschiedene Teile der Website. Sie kann mit einem einfachen Texteditor, wie Notepad, erstellt und über das Verwaltungs-Panel des Hostings oder einen FTP-Client in das Stammverzeichnis der Webressource eingefügt werden.
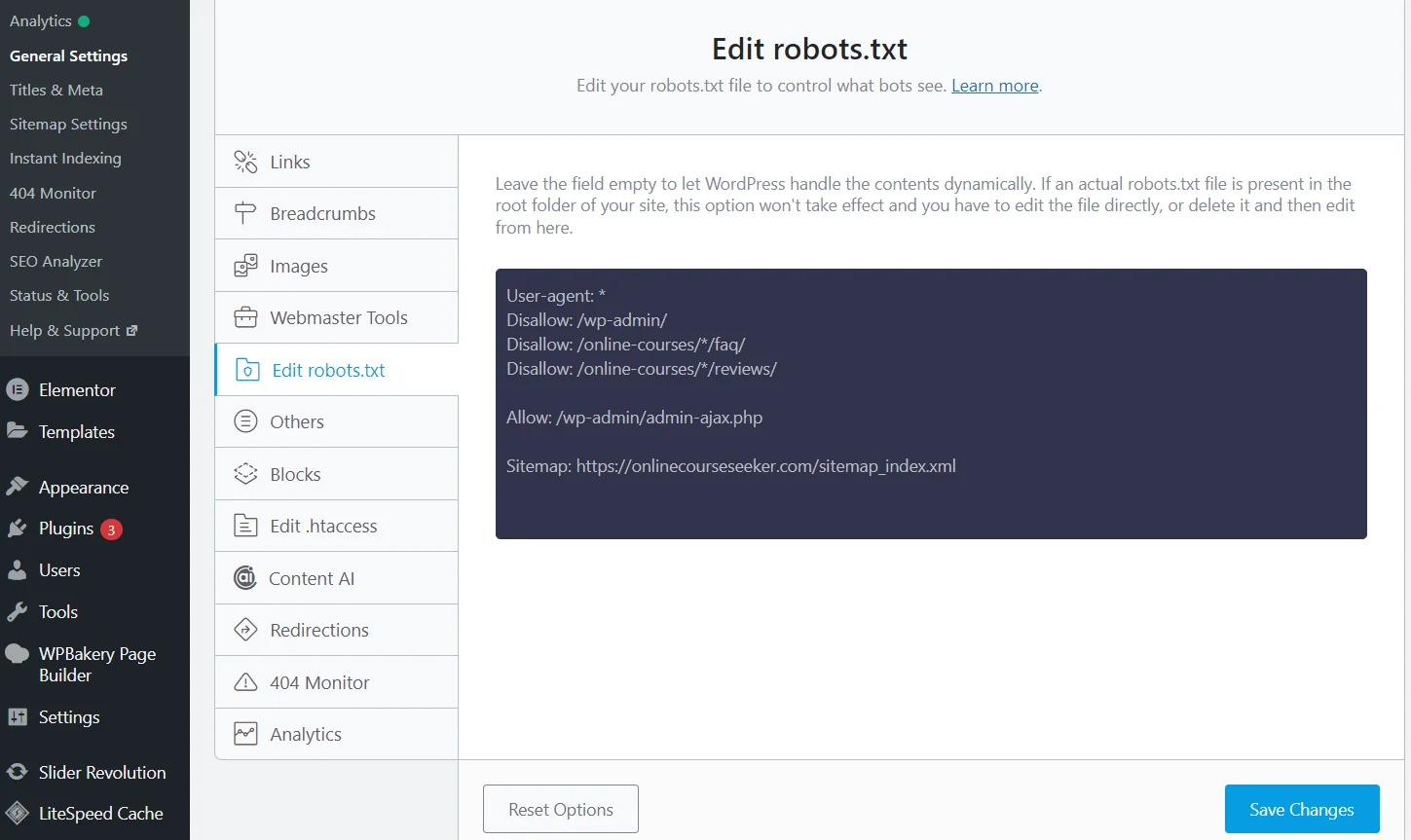
Bearbeitung der robots.txt mit dem Rank Math SEO-Plugin
Es gibt jedoch einen viel einfacheren Weg — SEO-Plugins. Es reicht aus, das Rank Math-Plugin (Yoast, All in One oder ein anderes) zu installieren und zu aktivieren, nach dem die Software die robots.txt-Datei erstellt. Außerdem wird sie automatisch aktualisiert, und die Daten können direkt auf der Website bearbeitet werden, sodass kein Wechsel zum Hosting-Verwaltungs-Panel erforderlich ist.
Sie können spezielle Regeln verwenden, um das Scannen bestimmter Seiten/Verzeichnisse zu verbieten:
- Bestimmte Seite. Zum Beispiel, wenn Sie die Seite für Kunden schließen müssen `https://example.com/private-page`. Fügen Sie in der robots.txt-Datei die Regel hinzu
User-agent: *
Disallow: /private-page
- Ganzes Verzeichnis. Um das Scannen des gesamten Verzeichnisses, zum Beispiel `https://example.com/private/`, zu verbieten, hilft der Code
User-agent: *
Disallow: /private/
- Dateityp. Um bestimmte Dateitypen, wie .pdf, von Suchmaschinen-Robotern zu schließen, hilft die Regel
User-agent: *
Disallow: /*.pdf$
Wichtig: Die robots.txt enthält eine Reihe von Regeln, aber Suchmaschinen-Roboter können sich nicht daran halten. Um eine Seite sicher von der Indizierung auszuschließen, empfehlen wir zusätzlich, das Meta-Tag `noindex` in den HTML-Code der Seite einzufügen:
meta name="robots" content="noindex"
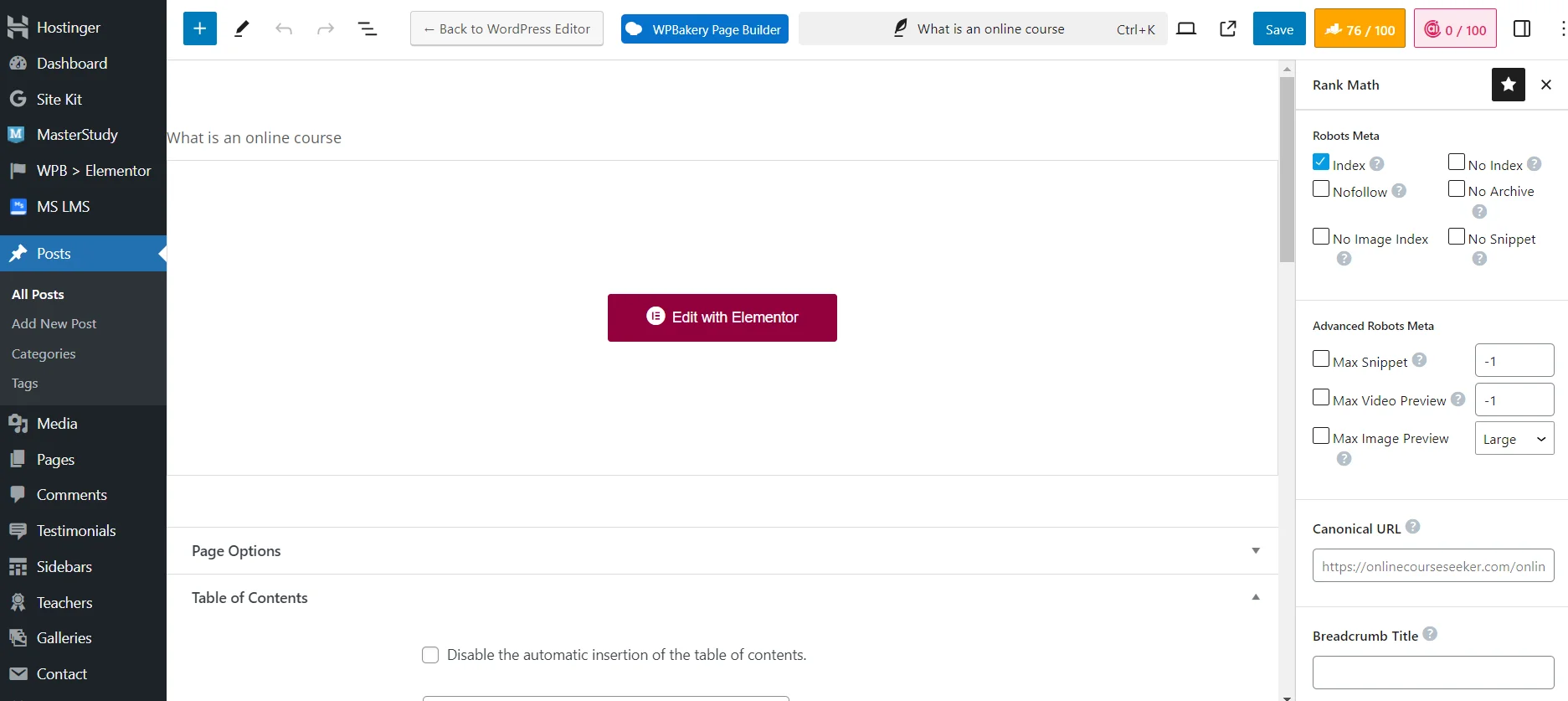
Einrichten der Sichtbarkeit der Seite für Suchmaschinen-Roboter mit dem Rank Math SEO-Plugin
Es ist jedoch viel einfacher, Seiten von der Indizierung über ein SEO-Plugin zu schließen. Es reicht aus, die erforderlichen technischen Einstellungen beim Hinzufügen oder Bearbeiten einer Seite vorzunehmen. Zum Beispiel können Sie `No Index` setzen, um das Material vollständig von Suchmaschinen-Robotern zu schließen. Oder `No Image Index`, um nur das Bild von der Indizierung auszuschließen.
Suchmaschinen-Roboter — sind wichtige Programme, die die Funktionsweise von Suchmaschinen erheblich vereinfachen, indem sie es ihnen ermöglichen, Websites schnell zu finden und zu rangieren. Wenn Sie die robots.txt-Datei optimieren, technische Probleme lösen, Sitemaps einrichten und interne Verlinkungen erstellen, können Sie den Crawlern den Zugang zu den benötigten Teilen der Webressource erleichtern. Das wird die Positionen dieser Seiten in den Suchergebnissen verbessern und somit die Anzahl der zielgerichteten Besucher erhöhen!








