
- Co to jest robot wyszukiwarki i jak działa
- Jakie są rodzaje robotów wyszukiwarek
- Po co właścicielowi strony wiedzieć o robotach wyszukiwarek
- Jak zarządzać robotami wyszukiwarek: plik robots.txt i inne narzędzia
Duże obciążenie serwera, brak w wynikach wyszukiwania docelowych stron i obecność niepotrzebnych — to tylko część trudności wynikających z braku zrozumienia zasady działania wyszukiwarek. Używają one specjalnych programów do skanowania stron internetowych, aby następnie dostarczać odpowiednie linki do zapytań użytkowników. Jeśli wiesz, co to jest robot i potrafisz skierować go w odpowiednim kierunku, uda się nie tylko uniknąć powszechnych problemów. Będziesz mógł poprawić szybkość indeksacji, zoptymalizować zasoby internetowe dla urządzeń mobilnych, szybciej wykrywać i usuwać błędy techniczne, co oznacza poprawę SEO i zwiększenie ruchu!
Przeczytaj także: Złe boty: jak szkodzą stronie i jak je zablokować
Co to jest robot wyszukiwarki i jak działa
Robot wyszukiwarki (pająk internetowy, skaner internetowy, crawler) — to oprogramowanie, które wyszukiwarki wykorzystują do zbierania informacji o stronie. Najpierw pająk internetowy przechodzi na stronę i skanuje jej zawartość, a następnie przekazuje informacje do bazy danych Google (Bing, Yahoo!). A na podstawie uzyskanych danych wyszukiwarka odpowiada na zapytanie użytkownika: podaje najbardziej odpowiednie odpowiedzi i klasyfikuje je według określonych kryteriów.
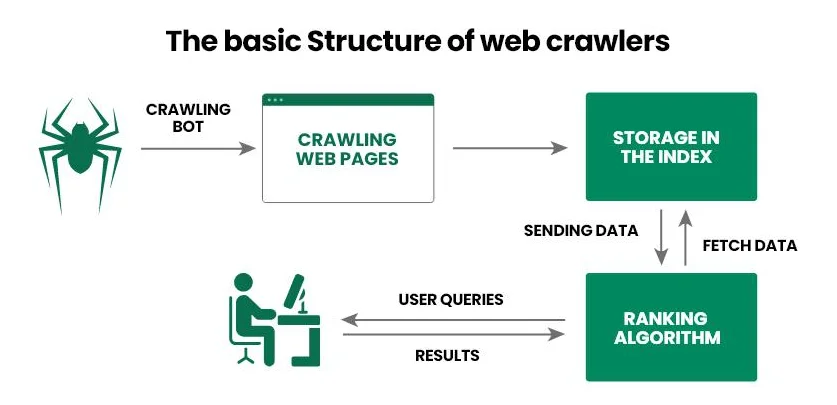
Przyjrzyjmy się zasadzie działania robota wyszukiwarki krok po kroku:
- Operator dostarcza crawlerowi zestaw startowy URL, na przykład listę linków do popularnych projektów internetowych.
- Pająk internetowy przechodzi przez linki, analizuje kod HTML dokumentu (metadane, tekst, obrazy itp.) oraz inne linki (wewnętrzne i zewnętrzne). Ponadto nowoczesne pająki mogą również przetwarzać JavaScript, co czyni je zdolnymi do skanowania dynamicznej zawartości.
- Uzyskane informacje wyszukiwarka przekazuje do bazy danych (indeks) do dalszego szczegółowego badania i przechowywania.
- Wyszukiwarka określa trafność strony dla konkretnych zapytań i przypisuje jej ranking, od którego następnie zależy pozycja w wynikach wyszukiwania.
- Po zaktualizowaniu informacji na już zaindeksowanej stronie, pająk internetowy wraca do niej, rejestruje zmiany i ponownie przekazuje informacje do bazy danych.
Przeczytaj także: Co to jest robots.txt i jak skonfigurować robots.txt dla WordPressa
Głównym zadaniem robota wyszukiwarki — jest zeskanowanie strony internetowej do dalszej indeksacji przez wyszukiwarkę. Dzięki temu wyszukiwarki zawsze mają aktualne informacje o zawartości projektu internetowego, użytkownicy — szybko otrzymują odpowiedź na swoje zapytanie, a właściciele stron — rozumieją, co należy poprawić, aby wyprowadzić stronę internetową na pierwsze pozycje w wynikach wyszukiwania.

Jakie są rodzaje robotów wyszukiwarek
Duże wyszukiwarki mają własne pająki internetowe, które wykorzystują do skanowania stron internetowych i indeksowania zawartości. Znając te roboty, możesz zablokować im dostęp do swojego zasobu internetowego lub, przeciwnie, uzyskać dostęp do narzędzi przyspieszających indeksację.
Najbardziej znane są następujące roboty wyszukiwarek:
- Googlebot. Używany przez wyszukiwarkę Google. Istnieją dwa oddzielne crawlers: Desktop skanuje wersję komputerową strony, a Mobile — mobilną.
- Bingbot. Pomaga wyszukiwarce Bing uzyskać aktualne informacje o zasobach internetowych i przeprowadzać klasyfikację według własnych algorytmów.
- Slurp Bot. Używany do uproszczonego tworzenia wyników wyszukiwania w wyszukiwarce Yahoo!.
- DuckDuckBot. Pająk wyszukiwarki DuckDuckGo, który podczas skanowania zasobów internetowych szczególnie zwraca uwagę na ochronę użytkowników.
- Exabot. Crawler mało znanej francuskiej wyszukiwarki Exalead, przeznaczony do skanowania i indeksowania stron według własnych zasad.
Wśród ukraińskich webmasterów najbardziej znany jest Googlebot, którym można zarządzać za pomocą Google Search Console (później dokładniej przyjrzymy się temu procesowi). Właściciele anglojęzycznych projektów internetowych stawiają nie tylko na Googlebot, ale także na Bingbot i Slurp Bot, co tłumaczy się dużym popytem na wyszukiwarki Bing i Yahoo!
Przeczytaj także: SEO na minimalnych poziomach – co właściciel strony może zrobić samodzielnie, aby promować stronę bez angażowania specjalistów
Po co właścicielowi strony wiedzieć o robotach wyszukiwarek
Czytając materiał, mogłeś pomyśleć: «Są różne roboty wyszukiwarek, dobrze wykonują swoje zadania, ale po co mi w ogóle o nich wiedzieć». Zrozumienie zasady działania pająków internetowych i znajomość najbardziej znanych z nich pozwala bezpośrednio wpływać na efektywność promocji strony w wynikach wyszukiwania. Możesz zabronić niektórym crawlerom dostępu do zasobu, zoptymalizować dokument, poprawić strukturę projektu internetowego, poinformować skanera internetowego o aktualizacji informacji lub dodaniu nowej strony. Dzięki temu możesz przyspieszyć indeksację i zwiększyć szanse na uzyskanie lepszej pozycji w wynikach wyszukiwania, co z kolei zwiększy liczbę docelowych odwiedzających.
Rozważmy, jak wykorzystać wiedzę o robotach wyszukiwarek w SEO:
- Optymalizować plik robots.txt. Oprogramowanie podąża za instrukcjami nie tylko wyszukiwarki, ale także właściciela zasobu internetowego. W tym celu wykorzystuje robots.txt — plik, w którym wskazane jest, które strony można skanować, a które należy ignorować.
- Unikać duplikatów. Czasami na stronie mogą pojawić się duplikaty treści, które mylą roboty wyszukiwarek, co odpowiednio obniża pozycje w wynikach wyszukiwania. Aby rozwiązać problem, można użyć tagów kanonicznych i przekierowań.
- Tworzyć linki wewnętrzne. Roboty wyszukiwarek zwracają dużą uwagę na linki wewnętrzne i zewnętrzne. Możesz wykorzystać tę informację, na przykład, łącząc linkami stare i nowe artykuły. Kiedy nowe strony mają linki wewnętrzne z już zaindeksowanych, pomaga to przyspieszyć ich sprawdzenie.
- Skonfigurować mapę strony. Zalecamy użycie dwóch map strony — dla robotów wyszukiwarek (sitemap.xml, przesyłana przez narzędzia dla webmasterów) i dla użytkowników (sitemap.html). Chociaż druga jest przeznaczona dla odwiedzających zasób internetowy, może pomóc również crawlerom, ponieważ, jak pamiętasz, analizując stronę, przechodzą przez wszystkie otwarte linki.
- Zwiększać autorytet. Pająki internetowe preferują domeny z dobrą historią. Możesz wykorzystać ten moment: zbuduj strategię link buildingu, aby uzyskać linki z autorytatywnych projektów internetowych, co odpowiednio zwiększy autorytet swojej strony.
- Usuwać błędy techniczne. Jednym z zadań właściciela zasobu internetowego — jest zapewnienie robotom wyszukiwarek swobodnego dostępu do stron. W tym celu należy monitorować błędy 404 i 500, problemy z przekierowaniami, uszkodzone linki, nieoptymalizowane skrypty i style.
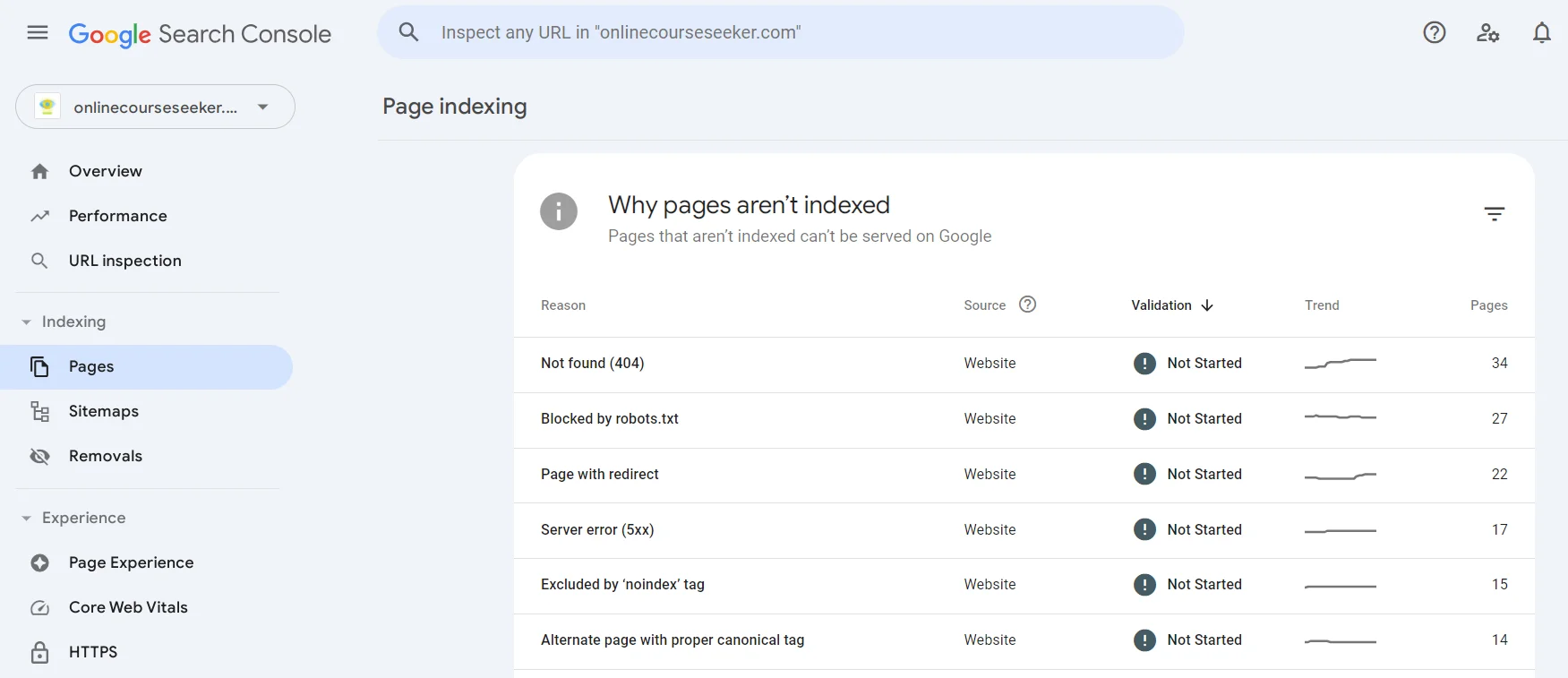
Aby znaleźć strony, które nie mogły zostać zaindeksowane, można skorzystać z Google Search Console w sekcji Strony. Możesz przejść do dowolnego istniejącego problemu (Nie znaleziono, Strona z przekierowaniem, Wykluczone przez tag «noindex» itp.), dowiedzieć się o nim więcej i znaleźć listę stron, które przez niego nie zostały zaindeksowane.
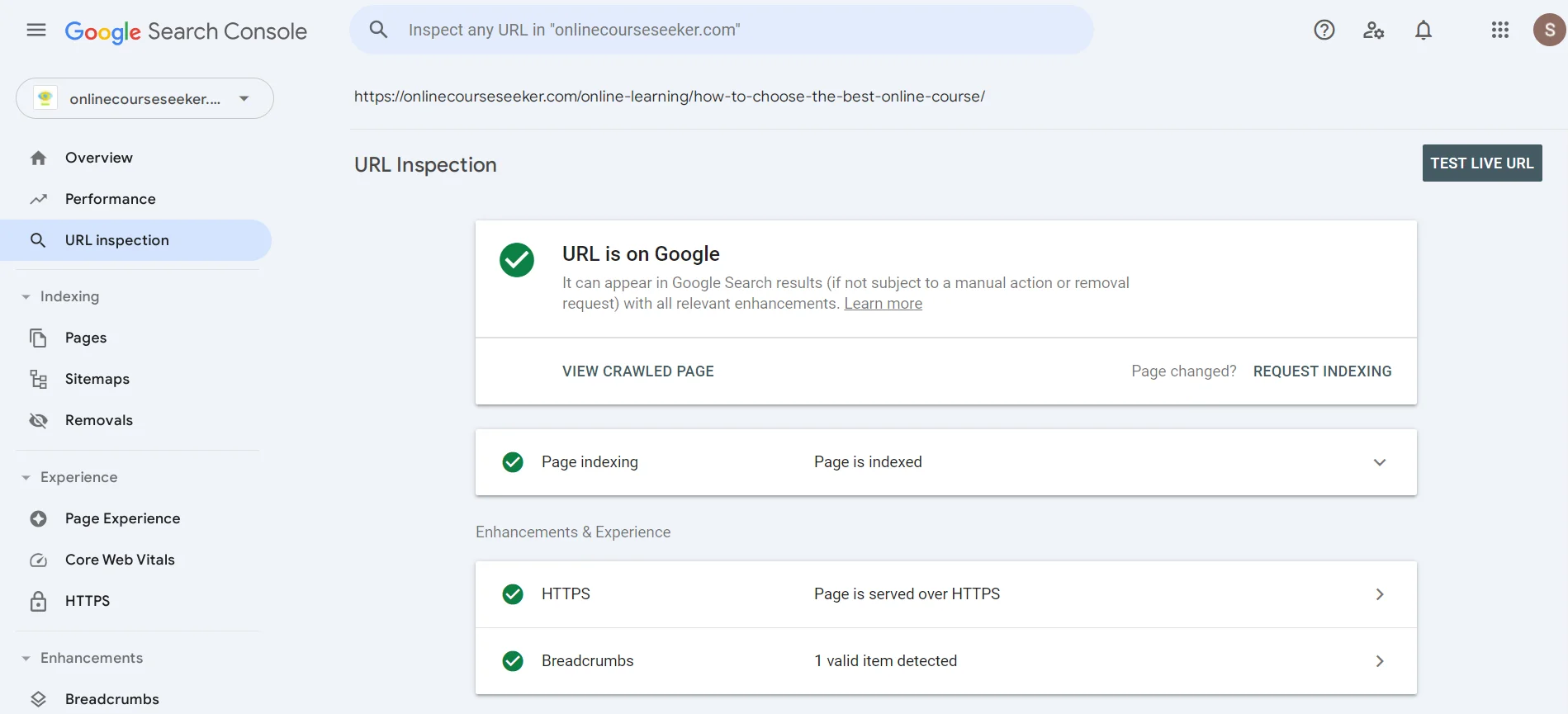
W wyszukiwarce można wpisać URL, aby dowiedzieć się, czy robot wyszukiwarki już sprawdził stronę. Jeśli zobaczysz komunikat o braku indeksacji, możesz kliknąć Prośba o indeksację, co oznacza, że wysyłasz crawlerowi wiadomość, aby zwrócił uwagę na twoją stronę wkrótce.
Przeczytaj także: Jak zbudować silny profil linków strony w 2024 roku
Jak zarządzać robotami wyszukiwarek: plik robots.txt i inne narzędzia
Plik robots.txt — to plik tekstowy do zarządzania dostępem robotów wyszukiwarek do różnych części strony. Można go stworzyć za pomocą zwykłego edytora tekstu, na przykład Notepad, i dodać do głównego katalogu zasobu internetowego przez panel zarządzania hostingu lub klienta FTP.
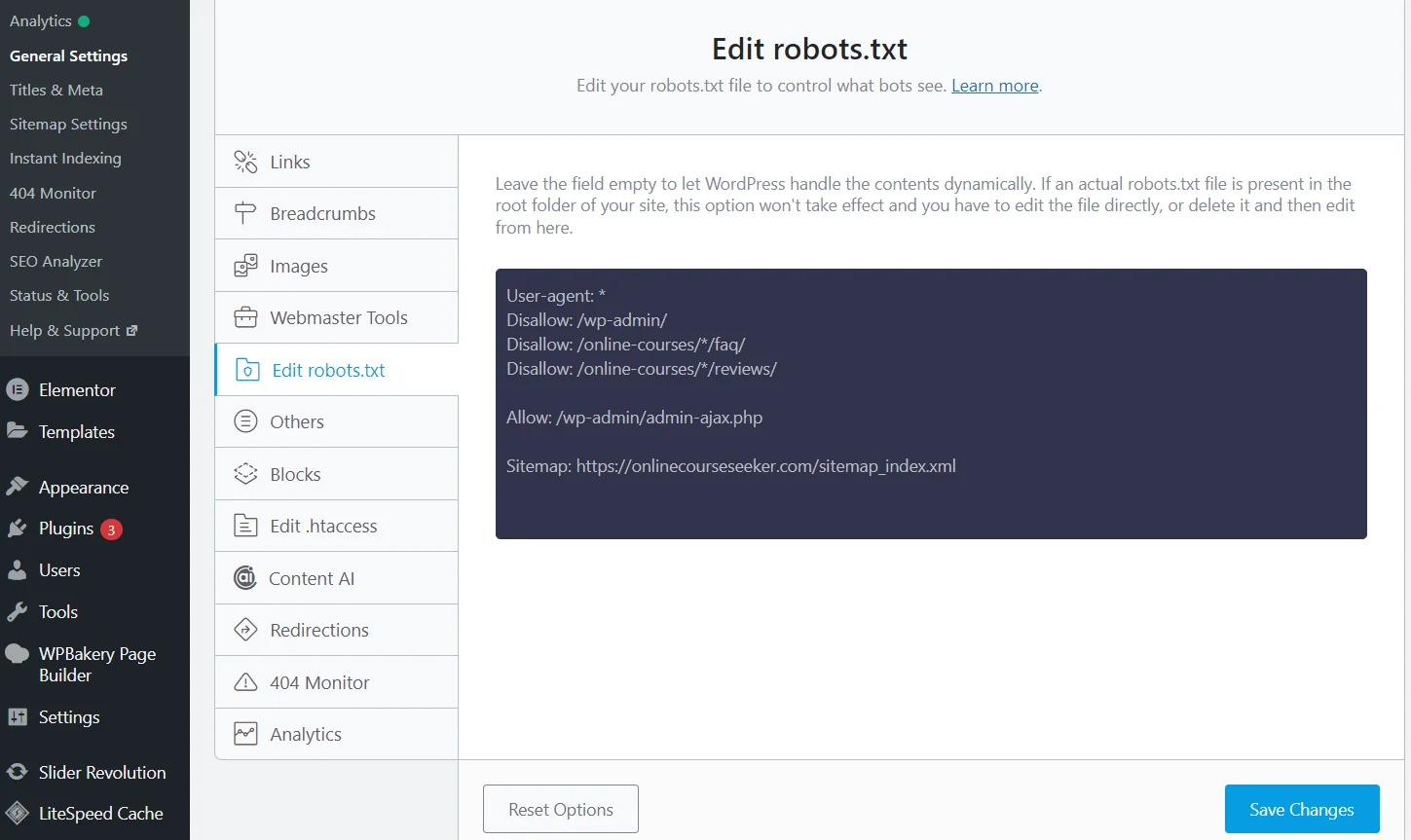
Edytowanie robots.txt za pomocą wtyczki Rank Math SEO
Jednak istnieje znacznie prostszy sposób — wtyczki SEO. Wystarczy zainstalować i aktywować wtyczkę Rank Math (Yoast, All in One lub inną), po czym system utworzy plik robots.txt. Co więcej, będzie go automatycznie aktualizować, a dane można edytować bezpośrednio na stronie, dzięki czemu nie trzeba przechodzić do panelu zarządzania hostingiem.
Możesz użyć specjalnych reguł, aby zabronić skanowania określonych stron/katalogów:
- Konkretną stronę. Na przykład, jeśli trzeba zamknąć stronę dla klientów `https://example.com/private-page`. Dodaj do robots.txt regułę
User-agent: *
Disallow: /private-page
- Cały katalog. Zabronić skanowania całego katalogu, na przykład `https://example.com/private/` pomoże kod
User-agent: *
Disallow: /private/
- Typ pliku. Zamknąć przed robotami wyszukiwarek określone typy plików, na przykład .pdf pomaga reguła
User-agent: *
Disallow: /*.pdf$
Ważne: robots.txt zawiera zbiór reguł, ale roboty wyszukiwarek mogą ich nie przestrzegać. Aby dokładnie zamknąć stronę przed indeksacją, zalecamy dodatkowo dodać metatag `noindex` do kodu HTML strony:
meta name="robots" content="noindex"
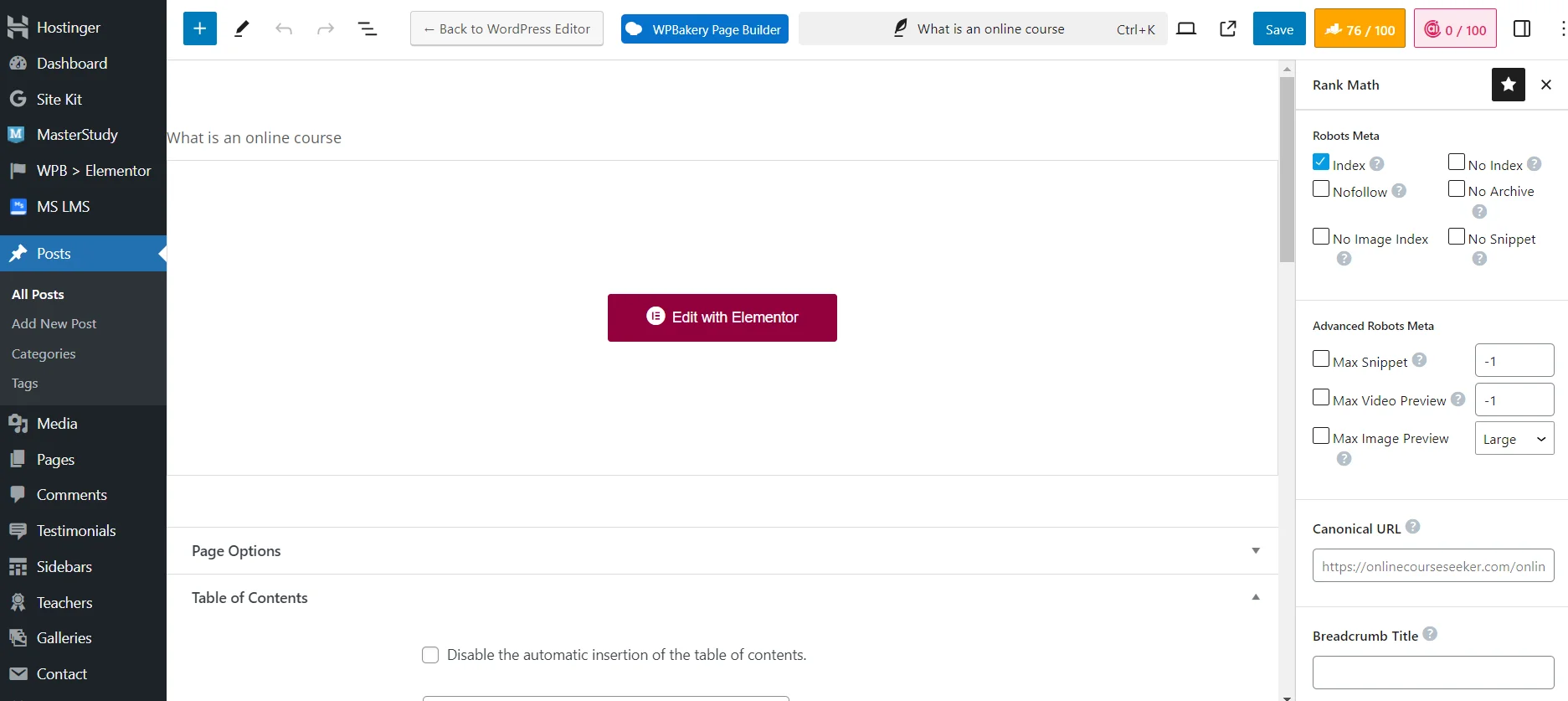
Ustawienie widoczności strony dla robotów wyszukiwarek za pomocą wtyczki Rank Math SEO
Chociaż znacznie łatwiej jest zamykać strony przed indeksacją za pomocą wtyczki SEO. Wystarczy użyć odpowiednich ustawień technicznych podczas dodawania lub edytowania strony. Na przykład, możesz ustawić `No Index`, aby całkowicie zamknąć materiał przed robotami wyszukiwarek. Lub `No Image Index`, aby zamknąć przed indeksacją tylko obraz.
Roboty wyszukiwarek — to ważne programy, które znacznie upraszczają działanie wyszukiwarek, pozwalając im szybko znajdować i klasyfikować strony. Jeśli zoptymalizujesz plik robots.txt, rozwiążesz problemy techniczne, skonfigurujesz mapy, stworzysz linki wewnętrzne, uda ci się uprościć crawlerom dostęp do potrzebnych części zasobu internetowego. A to pozwoli poprawić pozycje tych stron w wynikach wyszukiwania, co z kolei zwiększy liczbę docelowych odwiedzających!








