Od ponad 20 lat informacje ze wszystkich stron internetowych są archiwizowane i przechowywane w otwartym dostępie. Archiwum stron internetowych — to możliwość podróżowania w czasie i odkrywania, jaki kontent był umieszczany na stronach w różnych okresach ich istnienia. Informacje te są nie tylko niezbędne do pracy, ale także po prostu interesujące. Zgadzacie się, chcielibyście wiedzieć, jak wyglądał Google lub Facebook na początku swojej drogi? To może zrobić każdy użytkownik internetu.
W tym artykule opowiemy, jak poznać historię strony z archiwum internetowego, czym jest sam projekt, skąd się wziął i kto go stworzył.
Historia powstania Wayback Machine
Pod koniec lat 90. XX wieku dwóch wynalazców, Brewster Kahle i Bruce Gilliat, zastanowiło się nad problemem zachowania cyfrowej treści umieszczonej na stronach internetowych. Jeśli właściciel zasobu internetowego nie ma pieniędzy na opłacenie domeny lub po prostu nie jest zainteresowany dalszym utrzymywaniem strony, wszystkie umieszczone na niej materiały po prostu znikają. Podczas gdy gazety, książki czy filmy są archiwizowane i przechowywane, przestrzeń internetowa stała się jedynym źródłem informacji dostępnych tylko w czasie rzeczywistym.
W 2001 roku stworzyli organizację non-profit Internet Archive z bardzo poważnymi zamiarami — archiwizować cały internet. Projekt poszukiwania i zachowania stron internetowych został uruchomiony wcześniej, w 1996 roku, i nosił nazwę Wayback Machine — nawiązując do maszyny czasu.
W ciągu pięciu lat działalności, w momencie oficjalnego otwarcia, projekt zebrał już ponad dziesięć miliardów stron. A w 2020 roku archiwum stron internetowych zawierało 70 petabajtów danych (w jednym petabajcie – 1024 terabajtów). Obecnie na jego dedykowanych serwerach przechowywanych jest 625 miliardów stron internetowych.

Do czego można wykorzystać archiwum internetowe
To interesujące narzędzie jest przede wszystkim potrzebne tym, którzy pracują ze stronami internetowymi.
Robot wyszukiwawczy archiwum internetowego okresowo odwiedza strony zasobów internetowych i zapisuje wszystkie materiały strony.
Liczba skanowań robota Wayback Machine nie jest bezpośrednio związana z aktualizacjami na stronie, lecz odbywa się według własnego harmonogramu.
Takie archiwa mają praktyczne zastosowanie w wielu różnych przypadkach.
Przy zakupie domeny
Rejestrując domenę, nie możesz wiedzieć, czy jest nowa, czy była już wcześniej używana. I tylko sprawdzenie jej historii w archiwum internetowym może pokazać, czy coś było na niej wcześniej umieszczone. Informacja ta jest ważna z kilku powodów. Google «lubią» stare domeny — łatwiej je promować w wynikach wyszukiwania niż nowe. Jeśli masz taki adres, to tę sytuację można maksymalnie wykorzystać do promocji strony. Ale może być też «ciemna» strona domeny, która miała wcześniej innych właścicieli. Dlatego ważne jest nie tylko to, jak dawno stworzono domenę, ale także co dokładnie było na niej umieszczone.
Często webmasterzy celowo poszukują domen drop (z historią), aby szybciej promować stronę. Przed rejestracją takiego adresu sprawdzanych jest wiele różnych niuansów, wśród których historia treści strony.
Do umieszczania linków partnerskich
Rozwijając profil linków, linkbuilderzy umawiają się z różnymi platformami na umieszczanie linków do swojej strony. Często działa to jak wymiana linków.
Reputacja zasobu internetowego, z którym planuje się współpracę, ma duże znaczenie. W tym celu sprawdzany jest jego profil linków, organiczny ruch, wiek domeny i historia strony. Najbardziej ceniona jest współpraca ze starymi stronami, które rozwijały się przez wiele lat pod jednym adresem. Linki od takich darczyńców Google traktuje jako jakościowe. I odwrotnie — linki ze stron z wątpliwą historią mogą tylko zaszkodzić profilowi linków.
Aby znaleźć usuniętą treść
Jeśli treść została usunięta ze strony, istnieje duża szansa na jej odzyskanie z archiwum internetowego. Powody takiej potrzeby mogą być bardzo różne — od poszukiwania przypadkowo usuniętej treści własnej strony (chociaż lepiej jest tworzyć kopie zapasowe) po artykuły na cudzych stronach, które mogą być potrzebne do potwierdzenia publikacji informacji (na przykład, trzeba udowodnić fakt publikacji wiadomości).
W ten sposób można nie tylko znaleźć pojedynczą stronę, ale także odzyskać cały serwis.
Do badania historii rozwoju technologii IT
Programiści, webdesignerzy, copywriterzy, ilustratorzy stron potrzebują zrozumienia, jak zmieniał się i rozwijał Internet oraz poszczególne zasoby internetowe. Wayback Machine — to niewyczerpane źródło do badania stron w różnych latach ich istnienia na żywych przykładach. To naprawdę ten przypadek, kiedy można wsiąść do maszyny czasu i zobaczyć wszystko na własne oczy.
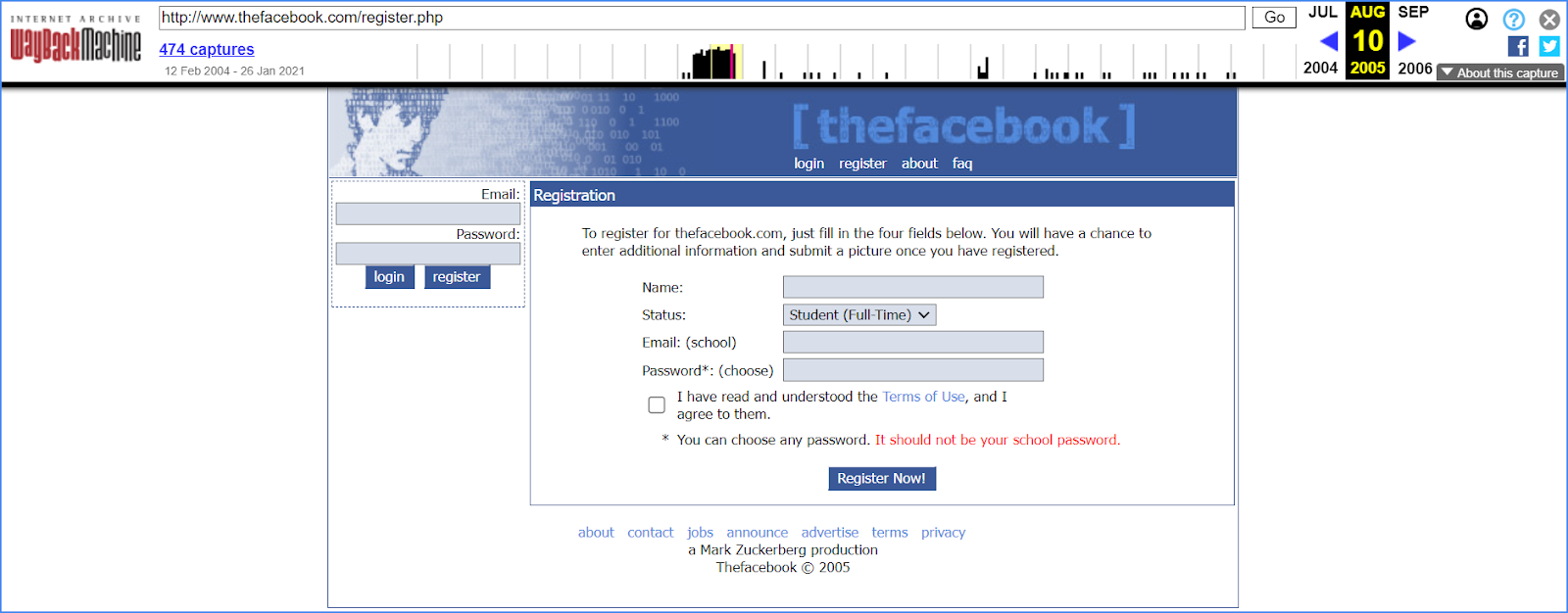
Na przykład, za pomocą archiwum internetowego możemy dowiedzieć się, jak wyglądał Facebook, gdy był siecią dla studentów w 2005 roku, a nikt nawet nie podejrzewał, że przekształci się w biznes z miliardowymi dochodami.
Archiwum stron może opowiedzieć także coś jeszcze — do 2005 roku strona na domenie facebook.com oferowała zakup oprogramowania AboutFace, które miało na celu pomoc firmom w tworzeniu telefonicznych katalogów pracowników. Główną cechą takich elektronicznych katalogów było posiadanie nie tylko kontaktów, ale także zdjęcia osoby. Jak widać, w tym projekcie już widać cechy przyszłej sieci społecznościowej.
Ale jest niezgodność: we wszystkich źródłach podana jest data założenia sieci społecznościowej w 2004 roku, ale jej interfejs pojawia się na domenie dopiero w 2005 roku. Odpowiedź jest prosta – w swoim pierwszym roku startup znajdował się na domenie thefacebook.com. Istnieje ona do dziś i przekierowuje na główny adres.
Jak widać, można wiele dowiedzieć się o historii strony, badając ją w archiwum internetowym.
Przeczytaj także: «Jak rysować w Midjourney: sieć neuronowa generuje obraz na podstawie tekstowych zapytań».
Wayback Machine — jak korzystać z archiwum stron
Przejdź do strony archiwum internetowego. Następnie należy wpisać w pasku wyszukiwania adres strony, a serwis wyświetli wszystkie statystyki.
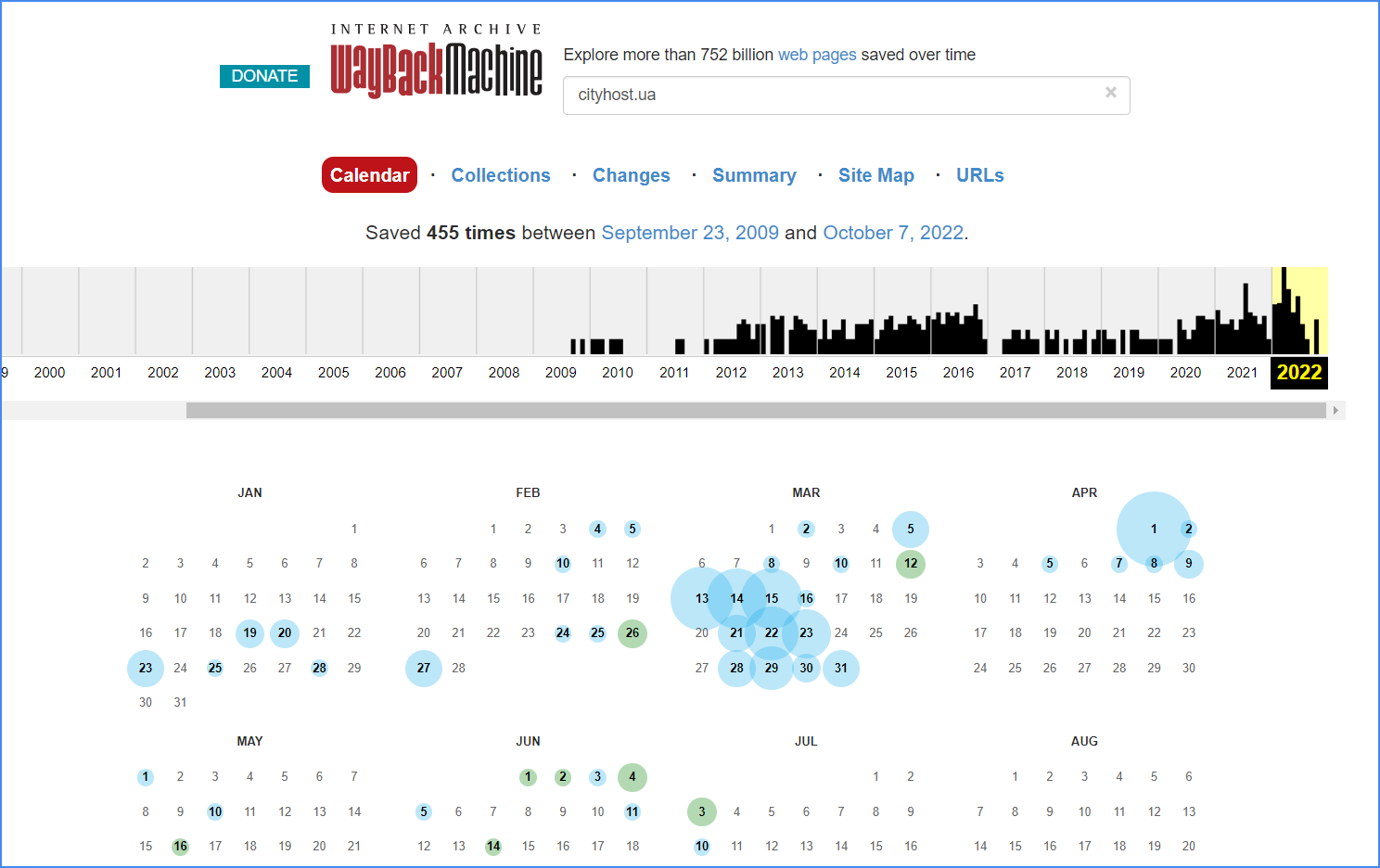
Na górze zobaczysz wykres aktywności robota, zbudowany na podstawie liczby zrzutów. Poniżej znajduje się kalendarz, w którym te zrzuty są zapisane. Stan strony można zobaczyć tylko za te daty, które są oznaczone niebieskimi i zielonymi kółkami – właśnie w te dni zapisano zrzuty strony. Następnie wybierasz jeden z zrzutów, klikasz na niego, a przed tobą otworzy się odpowiednia wersja strony.
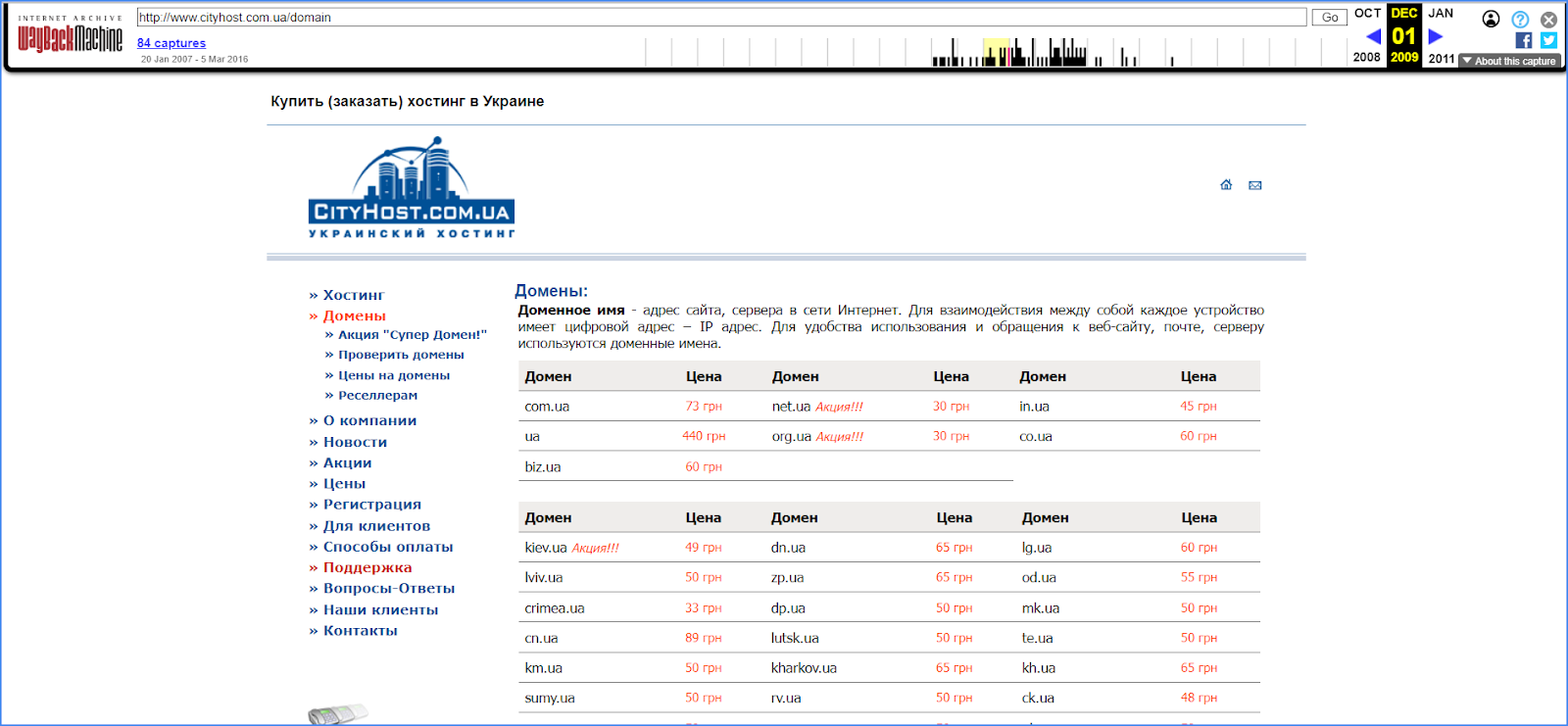
Wszystkie linki z menu w archiwum internetowym działają, więc możesz przejść przez całą stronę i zobaczyć wszystkie sekcje. Oto jak wyglądała strona Cityhost.ua w odległym 2009 roku.
Przeczytaj także: «Umieszczamy stronę w Internecie — jakie usługi kupować i ile one kosztują»
Oprócz domeny, w pasku wyszukiwania można wpisać także słowo kluczowe – wtedy otrzymasz listę stron promowanych pod tym kluczem.
Inne sekcje Internet Archive
Zespół archiwum internetowego postanowił przechowywać nie tylko strony, ale także «artefakty kulturowe w formie cyfrowej», jak sami to nazywają. To oddzielne pliki, w których zawarta jest cenna treść – wideo, zdjęcia, teksty, audio.
Archiwum internetowe – to tylko część projektu. Oprócz niego na stronie Internet Archive znajdują się jeszcze 4 sekcje:
-
Teksty
-
Wideo
-
Audio
-
Oprogramowanie
-
Obrazy
W archiwum internetowym można znaleźć wiele audiobooków (głównie w języku angielskim), nagrania z radiostacji, filmy dokumentalne, archiwa gazet, wydania wiadomości, filmy fabularne, muzykę, stare programy i gry.
Na przykład, oto takie interesujące rarytasy udało się znaleźć w «zakamarkach» archiwum:
-
Raport NASA z 1977 roku (start promu i Voyagerów)
-
Nagranie audio koncertu jazzowego dla radia
-
Super Mario 1994 (można zagrać bezpośrednio na stronie)
Specjalnie dobraliśmy radykalnie różne próbki, aby pokazać całe bogactwo materiału, który jest przechowywany w archiwum internetowym.
Ale nie wszystkie umieszczone w nim pliki muszą być stare — jest wiele nowego kontentu, który jest archiwizowany w tej chwili. Kiedyś i on stanie się dziedzictwem historycznym.
Obecnie w archiwum internetowym znajduje się:
-
38 milionów książek i tekstów
-
4 miliony obrazów
-
790 000 programów
-
14 milionów nagrań audio (w tym 240 000 koncertów na żywo)
-
7 milionów wideo (w tym 2 miliony programów telewizyjnych z wiadomościami)
Całe to bogactwo może pomóc nie tylko specjalistom z branży IT, ale także w każdej innej dziedzinie znaleźć potrzebne informacje. Wiele z tych plików jest dostępnych tylko w archiwum internetowym, co czyni je unikalną kolekcją danych cyfrowych.