Über 20 Jahre lang werden Informationen von allen Websites, die im Netz existieren, archiviert und öffentlich zugänglich gespeichert. Das Webarchiv von Websites — das ist die Möglichkeit, durch die Zeit zu reisen und herauszufinden, welcher Inhalt zu verschiedenen Zeitpunkten auf den Websites veröffentlicht wurde. Diese Informationen sind nicht nur für die Arbeit notwendig, sondern auch einfach interessant. Sind Sie nicht auch neugierig, wie Google oder Facebook am Anfang aussahen? Das kann jeder Internetnutzer tun.
In diesem Artikel erzählen wir, wie man die Geschichte einer Website aus dem Webarchiv erfährt, was das Projekt selbst ist, woher es stammt und wer es geschaffen hat.
Geschichte der Entstehung der Wayback Machine
Ende der 1990er Jahre dachten die zwei Erfinder Brewster Kahle und Bruce Gilliat über das Problem nach, digitalen Inhalt, der auf Websites veröffentlicht wurde, zu bewahren. Wenn der Besitzer einer Website kein Geld hat, um eine Domain zu bezahlen, oder einfach nicht an der weiteren Pflege der Website interessiert ist, verschwinden alle darauf veröffentlichten Materialien einfach. Während Zeitungen, Bücher oder Filme archiviert und gespeichert werden, ist der Internetraum zur einzigen Informationsquelle geworden, die nur in Echtzeit verfügbar ist.
Im Jahr 2001 gründeten sie die gemeinnützige Organisation Internet Archive mit sehr ernsthaften Absichten — das gesamte Internet zu archivieren. Das Projekt zum Suchen und Speichern von Webseiten wurde bereits früher, im Jahr 1996, gestartet und hieß Wayback Machine — nach dem Vorbild einer Zeitmaschine.
Nach fünf Jahren Arbeit hatte das Projekt zum Zeitpunkt der offiziellen Eröffnung bereits über zehn Milliarden Seiten gesammelt. Und im Jahr 2020 enthielt das Webarchiv von Websites 70 Petabyte Daten (in einem Petabyte sind 1024 Terabyte). Derzeit werden auf seinen dedizierten Servern 625 Milliarden Webseiten gespeichert.

Wofür man das Webarchiv nutzen kann
Dieses interessante Werkzeug ist in erster Linie für diejenigen nützlich, die mit Websites arbeiten.
Der Crawler des Webarchivs besucht regelmäßig die Seiten des Webressourcen und speichert alle Materialien der Website.
Die Anzahl der Scans des Crawlers Wayback Machine steht nicht in direktem Zusammenhang mit den Aktualisierungen auf der Website, sondern erfolgt nach einem eigenen Zeitplan.
Solche Archive haben in vielen verschiedenen Fällen praktische Vorteile.
Beim Kauf einer Domain
Wenn Sie eine Domain registrieren, wissen Sie nicht, ob sie neu ist oder bereits von jemandem genutzt wurde. Nur die Überprüfung ihrer Geschichte im Webarchiv kann zeigen, ob zuvor etwas darauf veröffentlicht wurde. Diese Information ist aus mehreren Gründen wichtig. Google «liebt» alte Domains — sie lassen sich einfacher im Ranking fördern als neue. Wenn Sie eine solche Adresse erhalten haben, können Sie diese Situation maximal für die Promotion der Website nutzen. Aber es kann auch eine «dunkle» Seite bei einer Domain geben, die zuvor andere Besitzer hatte. Deshalb ist es wichtig, nicht nur zu wissen, wie lange die Domain bereits besteht, sondern auch, was genau darauf veröffentlicht wurde.
Oft suchen Webmaster gezielt nach Drop-Domains (mit Geschichte), um die Website schneller zu fördern. Vor der Registrierung einer solchen Adresse werden viele verschiedene Nuancen überprüft, unter anderem die Geschichte des Inhalts der Website.
Für die Platzierung von Partnerlinks
Beim Aufbau eines Linkprofils vereinbaren Linkbuilder mit verschiedenen Plattformen die Platzierung von Links auf ihrer Website. Oft funktioniert dies als Linktausch.
Der Ruf des Webressourcen, mit dem eine Zusammenarbeit geplant ist, ist von großer Bedeutung. Dazu wird sein Linkprofil, organischer Traffic, das Alter der Domain und die Geschichte der Website überprüft. Besonders geschätzt wird die Zusammenarbeit mit alten Websites, die viele Jahre auf derselben Adresse gewachsen sind. Links von solchen Spendern werden von Google als qualitativ hochwertig angesehen. Umgekehrt können Links von Websites mit zweifelhafter Geschichte nur dem Linkprofil schaden.
Um entfernten Inhalt zu finden
Wenn Inhalte von der Website entfernt wurden, gibt es eine große Wahrscheinlichkeit, sie aus dem Webarchiv wiederherzustellen. Die Gründe für diesen Bedarf können sehr unterschiedlich sein — von der Suche nach versehentlich entfernten Inhalten der eigenen Website (obwohl es besser ist, dafür Backups zu erstellen) bis hin zu Artikeln auf fremden Websites, die zur Bestätigung der Veröffentlichung von Informationen benötigt werden (zum Beispiel muss der Fakt der Veröffentlichung einer Nachricht nachgewiesen werden).
So kann man nicht nur eine einzelne Seite finden, sondern die gesamte Website vollständig wiederherstellen.
Für die Erforschung der Geschichte der Entwicklung von IT-Technologien
Entwickler, Webdesigner, Texter und Illustratoren benötigen ein Verständnis dafür, wie sich das Internet und einzelne Webressourcen verändert und entwickelt haben. Die Wayback Machine — das ist eine unerschöpfliche Quelle für das Studium von Websites in verschiedenen Jahren ihrer Existenz anhand lebendiger Beispiele. Dies ist wirklich der Fall, wenn man in eine Zeitmaschine steigen und alles mit eigenen Augen sehen kann.
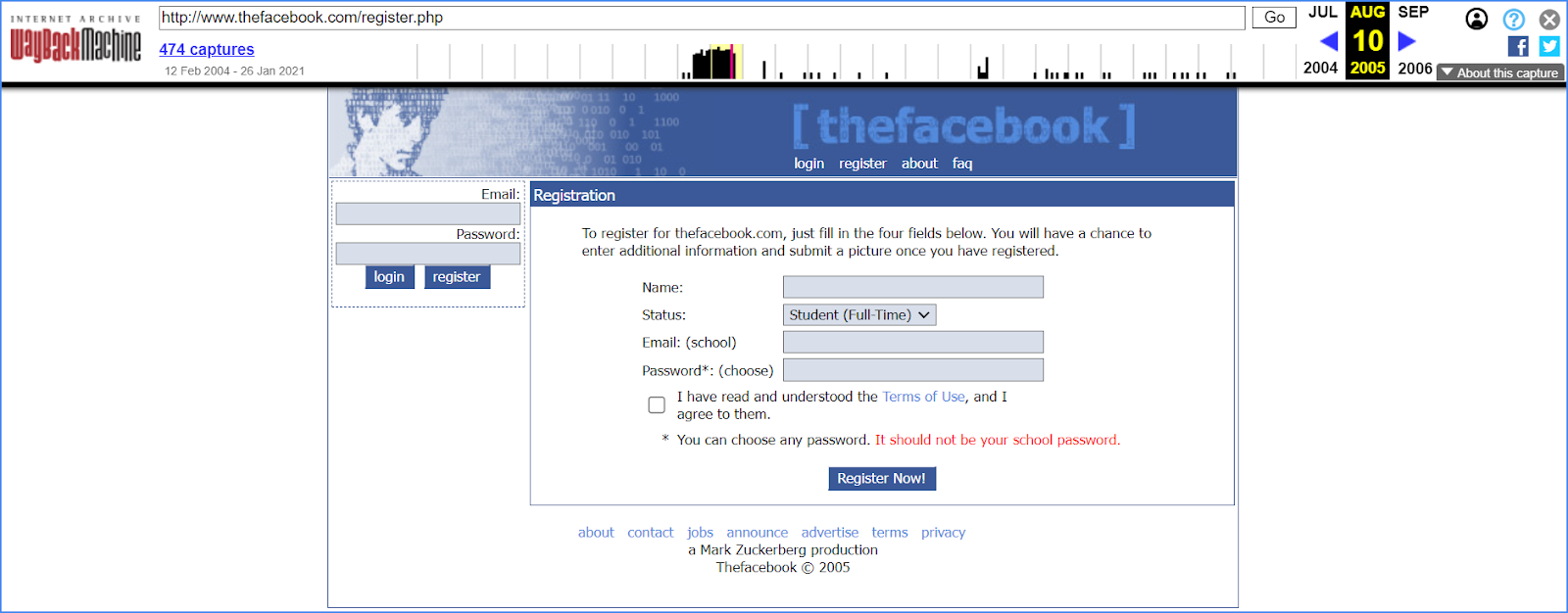
Zum Beispiel können wir mit Hilfe des Webarchivs herausfinden, wie Facebook damals aussah, als es 2005 ein Netzwerk für Studenten war, und niemand ahnte, dass es sich zu einem milliardenschweren Geschäft entwickeln würde.
Das Archiv von Websites kann auch noch etwas erzählen — bis 2005 bot die Website unter der Domain facebook.com an, die Software AboutFace zu kaufen, die dazu gedacht war, Unternehmen bei der Erstellung von Telefonverzeichnissen ihrer Mitarbeiter zu helfen. Das Hauptmerkmal solcher elektronischen Verzeichnisse war die Verfügbarkeit von Kontakten sowie Fotos der Person. Wie Sie sehen, zeigen sich in diesem Projekt bereits Züge des zukünftigen sozialen Netzwerks.
Aber es gibt eine Diskrepanz: In allen Quellen wird das Gründungsdatum des sozialen Netzwerks auf 2004 angegeben, aber sein Interface erscheint erst 2005 unter der Domain. Die Antwort ist einfach – im ersten Jahr war das Startup unter der Domain thefacebook.com registriert. Diese existiert immer noch und leitet auf die Hauptadresse weiter.
Wie Sie sehen, kann man viel über die Geschichte einer Website erfahren, indem man sie im Webarchiv studiert.
Lesen Sie auch: «Wie man in Midjourney zeichnet: Die KI generiert Bilder nach textlichen Anfragen».
Wayback Machine — wie man das Archiv von Websites nutzt
Gehen Sie über den Link zu der Website des Webarchivs. Geben Sie dann in die Suchzeile die Adresse der Website ein, und der Dienst zeigt Ihnen alle Statistiken an.
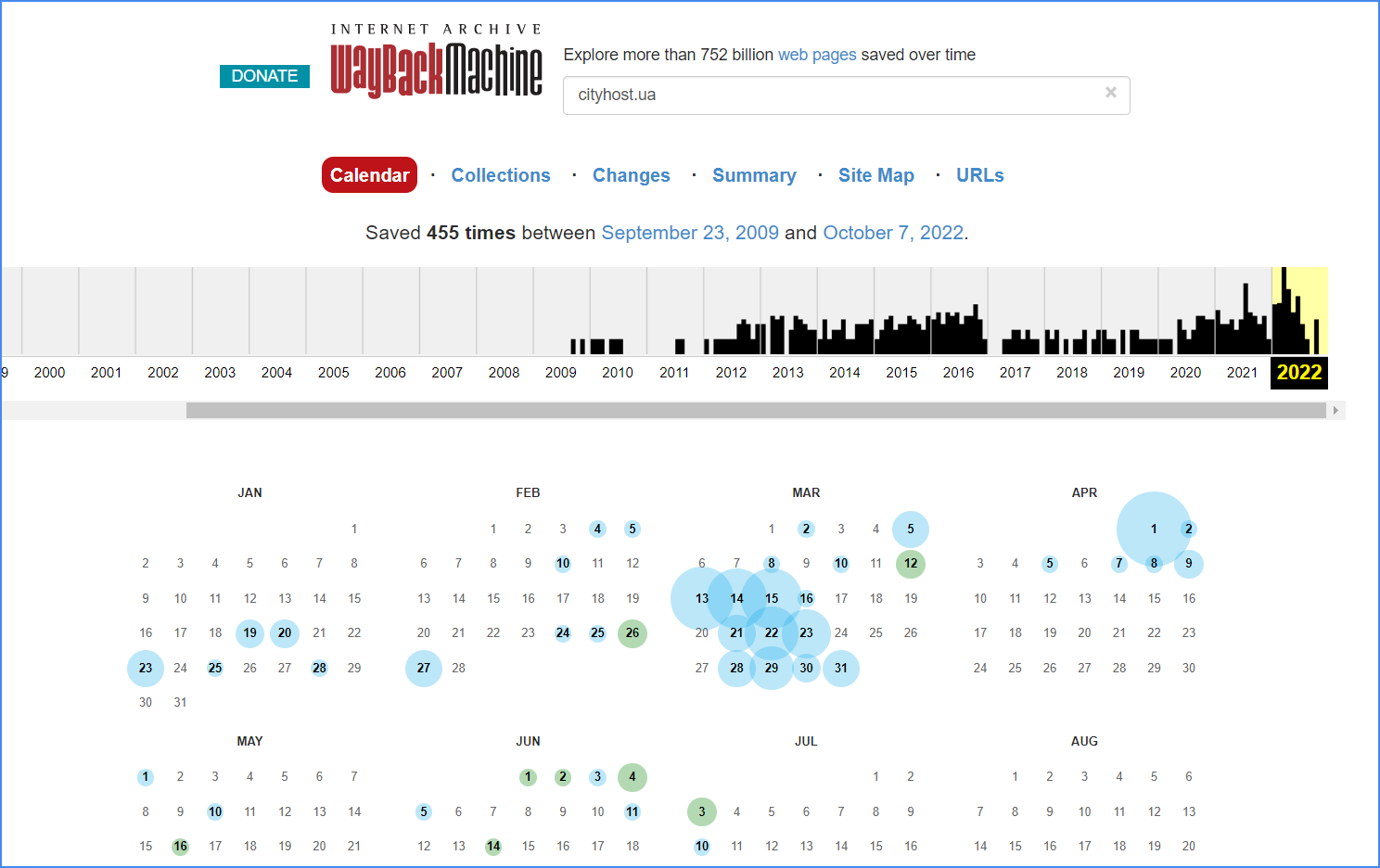
Oben sehen Sie ein Diagramm der Aktivität des Crawlers, das auf der Anzahl der Snapshots basiert. Darunter folgt ein Kalender, in dem diese Snapshots festgehalten sind. Den Zustand der Website können Sie nur an den Daten sehen, die mit blauen und grünen Punkten markiert sind – nur an diesen Tagen wurden Schnappschüsse der Website gespeichert. Wählen Sie dann einen der Snapshots aus, klicken Sie darauf, und vor Ihnen öffnet sich die entsprechende Version der Website.
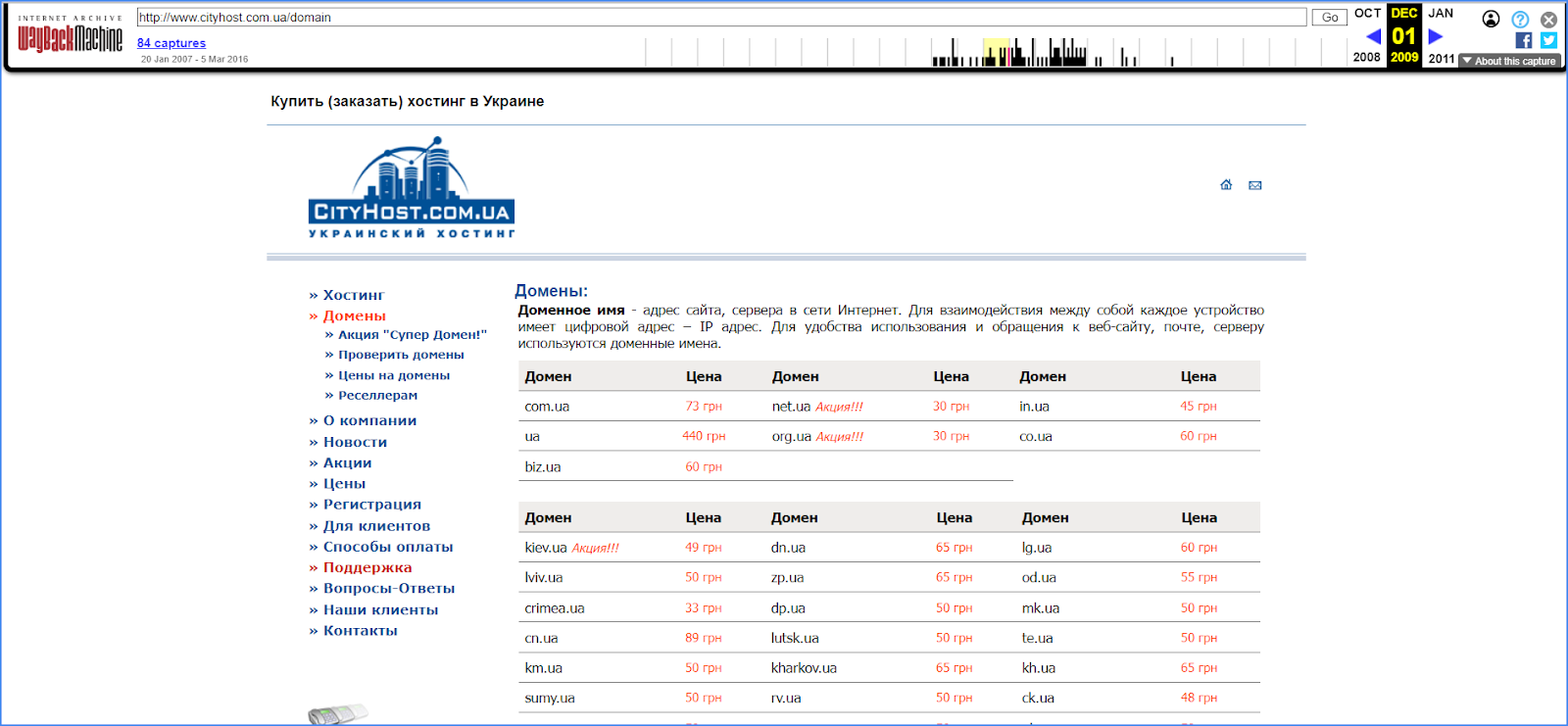
Alle Links im Menü des Webarchivs funktionieren, sodass Sie durch die gesamte Website navigieren und alle Abschnitte sehen können. So sah beispielsweise die Website Cityhost.ua im fernen Jahr 2009 aus.
Lesen Sie auch: «Website im Internet hosten — welche Dienstleistungen zu kaufen sind und wie viel sie kosten»
Neben der Domain können Sie auch ein Schlüsselwort in die Suchzeile eingeben – dann erhalten Sie eine Liste von Websites, die zu diesem Schlüsselwort beworben werden.
Andere Bereiche des Internet Archive
Das Team des Internetarchivs hat beschlossen, nicht nur Websites zu speichern, sondern auch «kulturelle Artefakte in digitaler Form», wie sie es selbst nennen. Dies sind einzelne Dateien, die wertvollen Inhalt enthalten – Videos, Fotos, Texte, Audio.
Das Webarchiv ist nur ein Teil des Projekts. Neben ihm gibt es auf der Website des Internetarchivs noch 5 Bereiche:
-
Texte
-
Videos
-
Audio
-
Software
-
Bilder
Im Internetarchiv finden Sie viele Hörbücher (hauptsächlich in englischer Sprache), Aufzeichnungen von Radiosendern, Dokumentarvideos, Zeitungsarchive, Nachrichtenberichte, Spielfilme, Musik, alte Programme und Spiele.
Zum Beispiel konnten wir in den «Dschungeln» des Archivs solche interessanten Raritäten finden:
-
NASA-Bericht von 1977 (Start des Shuttles und der Voyager)
-
Audioaufnahme eines Jazzkonzerts für das Radio
-
Super Mario 1994 (man kann direkt auf der Website spielen)
Wir haben absichtlich radikal unterschiedliche Beispiele ausgewählt, um die gesamte Vielfalt des Materials zu zeigen, das im Internetarchiv gespeichert ist.
Aber nicht alle veröffentlichten Dateien sind alt — es gibt auch viele neue Inhalte, die gerade jetzt archiviert werden. Eines Tages werden auch sie historisches Erbe werden.
Derzeit gibt es im Internetarchiv:
-
38 Millionen Bücher und Texte
-
4 Millionen Bilder
-
790.000 Programme
-
14 Millionen Audioaufnahmen (einschließlich 240.000 Live-Konzerte)
-
7 Millionen Videos (einschließlich 2 Millionen Ausgaben von Fernsehnachrichten)
All dieser Reichtum kann nicht nur IT-Spezialisten, sondern auch Fachleuten aus anderen Branchen helfen, die benötigten Informationen zu finden. Viele dieser Dateien sind nur im Internetarchiv öffentlich zugänglich, was es zu einer einzigartigen Sammlung digitaler Daten macht.